ELJonline: Visualizing Data in Real-Time
Sep 30, 2002 — by LinuxDevices Staff — from the LinuxDevices Archive — 3 viewsBruce explains how real-time data monitors differ from traditional debugging tools and are powerful allies in real-time software.
By definition, real-time systems interact with a dynamic world. This fact creates many challenges in designing, implementing and debugging real-time software. Fortunately for those of us who develop real-time embedded software, a number of excellent tools can help make these tasks a bit easier. Tools such as low-level monitors, in-circuit emulators and source-level debuggers are readily available and should be standard equipment in our software development toolkits. However, many problems are not visible from any of these traditional debugging tools. Debugging tools usually deal only with static values of stopped programs. Any tool that stops program execution simply cannot answer questions such as:
- How noisy is my sensor?
- How well is the controller working?
- When does my input queue cross the high-water mark?
- Is the input FIFO full?
- Or simply, why did my application do that?
These questions deal directly with the dynamic behavior of the real-world system that the software controls. Only a dynamic tool that analyzes a program as it runs can answer them.
Compare a traditional source-code debugger to a mechanic's garage. When you bring your car in for service, the mechanic stops the car, picks apart the pieces and sees what each part is doing. It's a valuable service that fixes many problems. However, it is a static test that cannot deal with dynamic, real-world issues.
Moreover, immediate feedback is immensely useful. Code changes, parameter-value changes and external actions are much easier to evaluate if the results are displayed immediately. Common examples include tweaking a control gain, testing a sensor, adding loads to the network and so forth. Live feedback really helps you get to know your system.
To understand your application, you need an on-line tool that can gather dynamic time histories without stopping or significantly slowing the real-time execution flow. This is similar to setting thousands of breakpoints per second in your code, automatically collecting values of all your variables and continuing — all without significantly slowing your system. The data is then presented to you live, while the system is running. We denote this type of tool a “real-time data monitor”. Real-time data monitors differ from traditional debugging tools and are powerful allies in real-time software development.
Historically, real-time data monitors were associated with proprietary, real-time operating systems (RTOSes) and sometimes required the use of special-purpose compilers. Today, however, real-time data monitors are available for applications running under Linux and compiled with standard GNU compilers. Consequently, many developers are beginning to recognize the benefits of real-time data monitors not only in traditional real-time applications but also in a wide variety of embedded and general-purpose applications.
Visualization Tools
Many other types of tools are designed for real-time applications. These include not only the debuggers and real-time monitor discussed previously, but also tools for operating system visualization and process-scheduling analysis. All of these help one to analyze or understand the system, though each does so in a different way.
In order to differentiate between some of these tools, let's use a couple more analogies. As we have seen, a source-level debugger displays static values of variables in stopped programs. It can be thought of as similar to a voltmeter. While useful for finding many problems, it's nearly useless for finding peak values, occasional glitches or time-dependent quantities like durations of events or noise characteristics.
Conversely, a real-time data monitor is more like a digital oscilloscope. It displays dynamic values of program variables with ease. For example, Figure 1 plots the number of messages in a queue over time — the horizontal axis. The data monitor is a window into your application. The monitor displays your data graphically, collects it for analysis and, optionally, will save the data to disk. Simply put, it helps you understand what your program does. Most new users of data monitors are surprised by the way the system operates. Visibility increases understanding and quickly leads to simple changes that result in much better operation.
An OS monitor, on the other hand, is more like a logic analyzer. It doesn't show analog values (program variables) but excels at displaying events, such as task switches, semaphore activity and interrupts. It lets you visualize the relationships and timing between operating system events. For example, you can measure how long it took for an interrupt to execute, how much later that interrupt was serviced and so on. It's also useful for watching and understanding task-switching activity — which processes are running, why processes are preempted, how long the task switch took and so forth. Issues like semaphore priority inversion, lock-outs and interrupt latency are easily revealed. Some common OS monitors include WindView from Wind River Systems for VxWorks targets, SpyKer from LynuxWorks for Linux and LynxOS targets and the Linux Trace Toolkit (LTT) for Linux targets. LTT is available as open source, and a screenshot is shown in Figure 2. While an OS monitor shows you how the operating system is running your application, a data monitor shows you what your real-time application is doing. This is a big difference. In fact, there's almost nothing the OS monitor can show that could be viewed with a data monitor and vice versa.
Both tools significantly increase productivity (and decrease developer stress), thereby decreasing product costs and speeding time-to-market. Perhaps more importantly, they greatly increase the quality of the end product. Embedded developers would be wise to have both types of tools in their development toolboxes.
Implementation Analysis
We have seen that a real-time data monitor enables you to analyze an application's interactions with the outside world. It allows you to explore and understand your system interactively. It directly shows when external events happen, how long operations take, the temporal characteristics of the system and variable histories, peaks and glitches. Therefore, the goals of a real-time data monitor are:
- Sample any variable's value over time.
- Allow variables to be modified on-the-fly.
- Collect and store the resulting time histories.
- Capture the data from interesting events.
- Display the data while the operation is in progress.
- Present the data to the user in intuitive displays.
- Minimally affect the system being tested.
Data Flow
For this discussion we assume the application is periodic in nature and has a repetitive loop or regular processing cycle. This class of applications includes all control and signal processing systems and most data-acquisition applications. Other types of applications also benefit from on-line monitoring, but sampled-data periodic applications impose the most demanding requirements on the data-flow design. The previous requirements suggest the general data-flow structure depicted in Figure 3. The main stages are:
- The application's variables are sampled and collected in response to some triggering event.
- The collected data is placed directly into local buffers.
- Data is taken from the buffers by a communications uplink program and, if needed, transmitted to the host by a low-priority process.
- A graphical user interface (GUI) on the host displays the data to the user.
At the most fundamental level, we need to collect values of variables at specified times. To do this, we need to decide which variables to sample, where these variables reside in memory, when each sample should be taken and when to start and stop sampling.
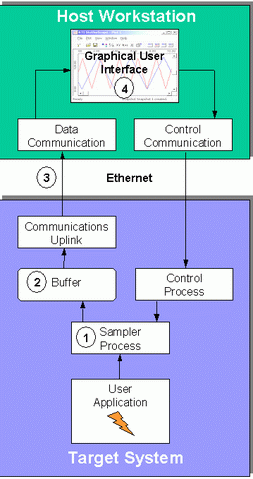
Figure 3. Control and Data Flow
Address Resolution
A data monitor must perform symbol-to-address resolution and then access the memory addresses that contain the variables of interest. These two tasks can be done through a variety of approaches, depending on the characteristics of both the target operating system and the target debugging tools. For example, in an operating system with a flat address space (i.e., one without virtual memory), address resolution and memory access may be as simple as traversing an operating system symbol table and then reading directly from the memory location. With embedded Linux, however, it is not quite as simple.
One method for performing address resolution and memory access under Linux is to link library routines directly into the executable program. In this case, the data monitor provides a simple API with functions to “register” variables and perform the data sampling. While this method has the drawback of requiring one to modify and recompile source code, it has a couple of benefits as well. It permits variables with local scope to be monitored and provides sampling that is synchronous to your application (see the next section on variable sampling).
In many instances, however, the desired variables to be monitored are not known a priori. In these cases, it is imperative that the data monitor has the ability to perform address resolution on the fly. Of course, variable scope affects whether or not a given symbol can be resolved on the fly — a variable needs to be either global or declared static to be resolved in this manner. Symbol-to-address resolution under Linux can be performed in a variety of ways, using a number of open-source tools and libraries.
Resolution of variable names to addresses is complicated further when handling compiler name mangling and complex data types, such as arrays, structures and classes. The data monitor should have ways of dealing effectively with both.
Variable Sampling
There are two basic ways to sample variable values: asynchronously or synchronously. Asynchronous sampling is simplest; we simply take a snapshot of the data values at regular intervals. The sampling period can be completely independent of the user application's activities. Synchronous sampling provides values at specified points synchronized in the application's execution. The period is set by some characteristic of the user's program.
Asynchronous Sampling
A process that wakes up at periodic intervals can do asynchronous sampling. For example, suppose an application process includes the following loop:
while(1) {
x++;
y = x;
}
Of course, this example has been simplified. In a real system, each pass through the loop would be initiated by some event, such as a clock tick. Asynchronous sampling could be performed by a process that simply loops:
while (1) {
Sample();
}
where the Sample() routine takes one sample of each variable it finds in the variable list. Again, this loop's rate would be controlled by some clock, presumably independent of the user process' execution. If x and y are in the variable list, this might produce the following data:
Sample No x y
1 1 1
2 2 2
3 3 2
4 5 5
5 5 5
... ... ...
Sample number 3 is inconsistent because x was sampled after the increment statement, but y was sampled before the assignment statement. Sample number 4 is inaccurate because the sample loop missed the case x = 4, y = 4.
Thus, asynchronous sampling cannot guarantee either data set consistency (where all samples in a set form a consistent view of the application state) or sampling accuracy (where the data from every loop of the application is sampled).
Synchronous Sampling
The best way to guarantee that a consistent set of data from each application loop is collected is to provide a user-callable routine that specifically samples the data. This routine is executed at the end of each application loop, at a time when all loop variables are in a known state. For example, this program
while(1) {
x++;
y = x;
Sample();
}
will produce the following results:
Sample No x y
1 1 1
2 2 2
3 3 3
... ... ...
Thus, we get consistent, accurate sampling — every loop is sampled and the samples occur at the same point of execution.
Triggering
At each sample time, a snapshot of each active variable is taken and stored in a buffer. Buffering allows the sampling process to be very fast and does not significantly slow the application loop. In many cases, users simply want to sample continuously.
However, you may be interested only in short sections of data before and after a significant event, such as a glitch or the arrival of a new command. This is especially true in fast systems that generate data at high rates. Collecting all the generated data is neither desirable nor practical.
Triggering — the ability to initiate sampling when a specified event occurs — can be used to catch the data you need. The entire collection, buffering and transmission sequence begins when the trigger is activated. The most flexible triggering allows any variable to be used as the trigger signal.
Delayed or premature triggering, and several other functions familiar from oscilloscope functions (hold-off, slope selection, etc.), are also useful. In addition, the application program should be able to set trigger parameters and fire the trigger directly from a software call.
Implementing the pre-triggering capability requires that the system be able to store possibly unwanted values in the buffer, in anticipation of the arrival of a trigger event. Thus, a circular buffer must be used; the oldest data is discarded when the buffer overflows before a trigger event arrives.
Write-Back
Another important feature of a real-time monitor is the ability to modify the content of variables on the fly. This write-back capability is useful in environments where parameters must be tweaked while simultaneously visualizing the effect of the adjustment. As mentioned previously, fine-tuning a real-time program can be an arduous task. Having to recompile for simple changes to constants and other parameters should be avoided if at all possible. A write-back capability can help minimize code changes and recompiles during testing.
Modifying values in a running program is powerful, but it can also be dangerous, especially if the running program controls hardware directly. Those of us that have used write-back features of real-time monitors probably have a horror story or two about what can happen when a data value is mistyped. The old adage, “with much power, comes much responsibility”, certainly applies in this case.
Data Transmission and Control
Once the data has been collected, it must be taken from the buffer, arranged into packets and sent to the host workstation. This process can involve significant overhead because a reliable protocol must be used (a tool used to diagnose problems cannot lose any data). Data transmission processes also may block at times while waiting for confirmation from the host workstation. For these reasons, the transmission must run as a separate process from the data-collection system. Within an RTOS, it usually can run at very low priority, thus using minimal system resources.
A real-time monitor can send a significant amount of data to the host. For example, a control system monitoring 50 4-byte floating-point variables at 1,000Hz will generate 200KB of data per second. While still well within the bandwidth of a 10Mb Ethernet local area network, efficiency must be considered in the design. On the other hand, some systems may generate only a few signals at rates of once or twice a second. This data must be displayed immediately or the user will notice the delay.
This wide range of required bandwidths presents a significant challenge. The goal is to strike a balance between full packets (for efficiency) and immediate transmission. An adaptive packetizing algorithm can be used to accomplish these goals.
Data flow is only part of the picture. We also need to communicate the changing list of variable names, types, etc., from the target system to the host. We additionally need to allow the GUI to change triggering and collection parameters, manage connections and communication failures and so on. In other words, we require control flow as well as data flow.
Because control flow is sporadic and of lower urgency than the process collecting data, the control process can run as a separate task or process. Its purpose is to process requests from either the GUI or the application code.
One of the greatest challenges of the control-monitoring dæmon is to allow both GUI-initiated requests and application-initiated requests to occur simultaneously. We already have encountered one of these — the software triggering function. There are many others. The application code interfaces must, at a minimum, install variables and change buffering parameters. A fully functional implementation also lets the application code set up triggering conditions, change sampling rates and characteristics, query and change variable definitions and so on. Because the GUI also can affect many of these functions, conflicts must be resolved.
Operator Interface
Finally, we come to the issue of operator interface. Our data-collection system will now feed new data to the host as soon as it is produced. The GUI must present this data in an intuitive manner.
The most important requirement, obviously, is for simple plotting capability. Unlike most plotting packages, the full extent of the data will not be known before the plot must be started. This “get a point, plot a point” requirement is significantly harder than the “plot an entire line” requirement typical of most plotting programs. In fact, as with the data transmission facility, the plotting package must be prepared to plot a large number of points quickly in some cases, and a very small number (even one at a time) in other cases. We cannot afford the luxury of waiting for a set number of points to accumulate before plotting.
This raises several issues. Consider the problem of plotting six 1,000-point curves on the same plot. If the data is all known ahead of time, we can simply plot six 1,000-point lines. Drawing packages have routines optimized for plotting multipoint lines quickly. We also can auto-scale the plot to insure that everything fits nicely. However, if we receive these points individually, and we have a requirement to plot them as soon as they are received, we need to plot 6,000 individual points — 6,000 individual calls to the plotting routine. Simple optimizations, such as checking for multiple points for each line waiting to be plotted, can speed this considerably.
Conclusion
Engineers need to see what's going on inside their embedded real-time systems. Visualization tools change the way we interact with the systems we are developing. The resulting productivity increases shorten the development cycle significantly, increase quality and make real-time programming more productive.
Virtually all real-time software has variables that are interesting and enlightening to monitor. By providing a direct window into the application, real-time data monitors allow the engineer to see what's happening inside their application software. This helps us understand the software and its interactions with the real world and become more productive developers.
If you're currently developing real-time software, chances are you're already using a primitive real-time monitor — one that's built into C and C++ languages: printf(). Perhaps it is time to consider upgrading to a less-intrusive, more powerful tool.
An Example Application
Veraxx Engineering uses the StethoScope real-time data monitor when developing software for high-performance flight simulators. StethoScope, from Real-Time Innovations, is available for a variety of operating systems including VxWorks, Windows, Solaris and Linux. The software that Veraxx develops is used to simulate some of the most advanced aircraft in the world — including the USMC's CH-53E and CH-46E helicopters.
Veraxx uses Linux as the operating system for their simulation host computers. The host computer is the brain of a flight simulator — executing the code to simulate everything from the aircraft aerodynamics to the simple illumination of caution and warning lights in the cockpit. The code that Veraxx develops is mostly in C++ and Ada. For off-line debugging they generally use the GNU debugger, but they rely upon the versatility of StethoScope to perform a variety of real-time debugging tasks.
During software development, Veraxx uses StethoScope for subsystem debug and test. Since the simulator hardware is often unavailable, simulation engineers use StethoScope's monitoring windows to alter and tweak variables on the fly. If the Instructor/Operator Station (IOS) is also not available, they will use StethoScope to insert malfunctions and introduce failure conditions — viewing how the code responds via real-time plots. All of this is done without stopping the executing code.
When the flight simulator hardware is integrated with the software, a real-time monitoring tool becomes even more valuable. Intrusive debuggers cannot be used when simulator hardware, such as a motion system, is tested with the software. A motion system consists of large hydraulic actuators that suspend a simulated cockpit ten feet above the ground. These actuators provide movement in six degrees of freedom, mimicking actual aircraft flight. To test the fidelity of the simulation fully, the software must be evaluated when driving the motion system at full speed — providing updates at 60Hz. It is in this type of scenario where Veraxx has found StethoScope to be most valuable in detecting bugs. For example, when a slight oscillation or jitter is felt in the motion system, Veraxx engineers quickly can capture and plot data being sent to the motion system. If an anomaly is detected, further data collection and plotting can be done easily to pinpoint the nature of the problem, with virtually no setup time.
To ensure proper training, flight simulation software must be verified extensively with actual flight test data. Veraxx collects and plots data using StethoScope during simulated flights and then compares it with pre-recorded flight data taken from the actual aircraft. In this way, the simulator objectively can be proven to have the same flight characteristics as the aircraft.
Finally, simulated aircraft also must meet stringent transport delay requirements. Transport delay in a simulator is the latency that occurs between operator input and the simulated response to that input. For example, if a pilot abruptly moves a flight stick in an evasive maneuver, the simulator should respond in about the same amount of time as the actual aircraft — within 100 milliseconds or so. Veraxx uses StethoScope during acceptance testing to plot and verify the transport delay through the simulator.
Copyright © 2002 Specialized Systems Consultants, Inc., publishers of the monthly magazine Linux Journal. All rights reserved. Embedded Linux Journal Online is a cooperative project of Linux Journal and LinuxDevices.com.
This article was originally published on LinuxDevices.com and has been donated to the open source community by QuinStreet Inc. Please visit LinuxToday.com for up-to-date news and articles about Linux and open source.