Article: Debugging “configure” (when programs won’t build)
Jan 5, 2004 — by LinuxDevices Staff — from the LinuxDevices Archive — viewsAll too often, checking the README of a package yields only the none-too-specific “Build Instructions: Run configure, then run make.” But what about when that doesn't work? In this article, Peter Seebach discusses what to do when an automatic configuration script doesn't work — and what you can do as a developer to keep failures to a minimum. After all, if your build process doesn't work, users are just as badly off as if your program doesn't work once it's built.
by Peter Seebach
All too often, checking the README of a package yields only the none-too-specific “Build Instructions: Run
configure, then run make.” But what about when that doesn't work? In this article, Peter Seebach discusses what to do when an automatic configuration script doesn't work — and what you can do as a developer to keep failures to a minimum. After all, if your build process doesn't work, users are just as badly off as if your program doesn't work once it's built.
A lot of open source programs come with configure scripts these days. One purpose of such a script is to automate the guesswork of targeting a new system. In times of yore, programs came with a Makefile that had half a dozen different sets of compiler flags or options, all but one of which were commented out, and a note saying “select the appropriate flags for your system.” For more comprehensive sets of configuration options, there might also have been a large C header called config.h containing a few dozen flags to set, depending on host system variables.
The first approach was simply to have #ifdefs in code for the two systems supported; for instance, BSD and System V. As the number of Unix variants increased, it became more practical to have #ifdefs for each feature. Per-system code produced this:
|
Per-feature code produced this:
|
The second was easier to adapt to a new system, but required a great deal of work from the developer. Now, with dozens of potential target systems, developers benefit a lot from using the second method, except they can now build the configuration header file automatically. One way to do this is by using GNU autoconf code to build a configure script. This script does the necessary tests and creates a configuration header file with the right values.
Another function of such a script is to set up predefined variables in a consistent way. One of the persistent problems with hand-editing flags was modifying the Makefile (for instance to install it in /usr/gnu instead of /usr/local) and then forgetting to modify the corresponding values in header files. Of course, this resulted in the compiled program not knowing where to find its own data files. One of the benefits of a configure script (if the maintainer has done things right) is that it automatically creates a consistent installation.
Developers, please note that another benefit of a good configure script is that it should allow users to specify things like a preference for /usr/gnu over /usr/local.
Finally, a configure script can do a lot of the work of guessing which optional packages are installed, or which requirements are missing. For instance, a program designed to work with the X Window System may well want to know where X has been installed, or even whether X has been installed.
How is this all possible?
Compile and try again
A great deal of what configure does happens by a simple mechanism. To see this yourself, design a small test program that will compile if and only if the desired condition is true. Save it in a temporary file and try to compile it. For instance, imagine that you wish to know whether or not the X Windowing System has been installed in the path /usr/X11R6/. One way to do it would be to make a test program like this:
#include 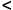 X11/X.h>
X11/X.h>
int main(void) { return 0; }
Now, if you tell the compiler to try to compile this, it will succeed if and only if (directory)/include in the compiler's include path. If you get a value that allows the sample file to compile, then you've got the right include path.
Note that there are predefined tests for all sorts of things in autoconf. Whenever possible, use these tests instead of writing your own. This has multiple benefits. First, new versions of autoconf may improve these tests and fix bugs in them that you'd otherwise have to fix yourself. Second, it saves you time. Of course, better still is avoiding a test entirely. If you can reasonably conclude that a test is unnecessary (for instance, even machines with bytes larger than 8 bits are still required to have sizeof(char) be 1), you can omit the test entirely.
Some tests are functional tests; it's not enough to know that a function called memcmp() is provided, it has to actually have the correct semantics. Often, these are tests for very obscure bugs that have only ever been noted on one or two platforms. These tests will actually run the test program and check its output. Test programs generally use the standard Unix conventions: they return 0 in the event of a successful run and some non-zero value in the event of failure.
Once you have enough of these, you can use them to automatically determine necessary compiler flags and definitions to put in a header file somewhere. Often, configure scripts will allow users to override some or all of the guesswork and provide known-good answers.
Look especially at a case like, say, a system with a brokenmemmove(). If you don't know that it has a bug that affects only a few programs, you may build a program and put it in production without knowing that you'll see occasional catastrophic failures.
In many cases, the net result of a long and complicated configure script is this: the target system provides every standard feature used by this program, and they all work correctly. Why not just set the flags by hand, in such cases? This is often quite reasonable for developers, but it is less reasonable for many users. Users may not be aware that their Linux distribution happens to have a given bug. They may not be clear on what packages are installed, or where. The script helps the people who need the most help do the most common thing. The extra work it can produce when the script goes wrong is probably a fair price to pay.
What goes wrong?
Now that you've got a basic idea of what configure does, you can start learning what goes wrong. There are two ways configure can fail. One is when configure is correct, and your system really does lack a prerequisite. Most often, this will be correctly diagnosed by the configure script. A more disturbing case is when configure is incorrect. This can result either in failing to produce a configuration, or producing an incorrect configuration.
When configure guesses right, and you lack a prerequisite, all you have to do is obtain the missing prerequisite. Once you've found and installed it, re-run the configure script that was complaining about the missing prerequisite, and all should be well. (Be sure to remove the file config.cache, which contains cached results from previous tests; you want configure to start over from the top.)
If you're developing a configure script, make sure you give a meaningful error message. If you're testing for a function that is part of a popular add-on package, don't tell the user the name of the missing function — tell the user the name of the package they need. Make sure to put prerequisite information in the README file. And please, please, tell people what versions of other packages you tested with.
Of course, even after the prerequisite has been installed, the config script might not find the newly installed program. In that case, you're back to what to do when configure guesses wrong.
Read the documentation
Almost always, the first thing you should try when configure fails is to run configure -h and checking the list of arguments. If it's not finding a library you're sure is installed, there may be an option to let you specify an alternative location for that library. You may also be able to disable or enable certain features. For instance, the configure script used for Angband (a Roguelike game) has an optional flag, --enable-gtk, to tell it to build with GTK support. Without this flag, it won't even try.
You may have to set up some fairly elaborate variables for a configure script if your system is strangely configured, and you will almost certainly have to do something pretty weird if you're cross-compiling. A lot of problems can be solved by specifying a value for CC, the variable configure uses for the C compiler. If you specify a compiler, configure will use that one, rather than trying to guess which one to use. Note that you can specify options and flags on the command line this way. For instance, if you want to compile with debugging symbols, try this:
CC="gcc -g -O1" ./configure
(This assumes you're using a sh-family shell; in csh, use setenv to set the environment variable CC.)
Reading config.log
When the configure script runs, it creates a file called config.log, which contains a log of tests run and the results it encounters. For instance, a typical stretch of config.log might look like this:
Listing 3. Typical contents of config.log
|
If I were on a system where -lsun ought to provide getpwnam(), I'd have been able to look at the exact command line used to check for it, and the test program used. Debugging these a bit would then give me enough information to tweak the configure script. Note the helpful line numbers; this test starts on line 2,826 of the configure script. (If you're a shell programmer, you may enjoy reading the section of the configure script that arranges to print line numbers; in shells that don't automatically expand $LINENO to a reasonable value, the script makes a copy of itself using sed, with the line numbers filled in!)
Reading the log file is the best starting point for understanding a test that failed or produced surprising results. Note that sometimes the test that fails is not actually important and is only being run because a previous test failed. For instance, configure may abort because it can't find an obscure library you've never heard of, which it is only trying to find because a test program for a feature in your standard C library failed. In such cases, fixing the earlier problem will eliminate the second test entirely.
Buggy test programs
There are a few other ways in which configure can occasionally guess wrong. One is when the test program isn't correctly designed and may fail to compile on some systems. As an example, consider the following proposed test program for the availability of the strcmp() function:
Listing 4. Test program for availability of strcmp()
|
This program is written to avoid using the strcmp() is present in the library, the program will compile and link correctly; if it isn't, the linker will be unable to resolve the reference to strcmp(), and the program will fail to compile.
On one version of the UnixWare compiler, references to strcmp() were translated automatically into an Intel processor's native string compare instruction. This was done by simple substitution of the arguments passed to strcmp() into a line of assembly code. Unfortunately, the sample program called strcmp() with no arguments, so the resulting assembly code was invalid and the compile failed. In fact, you could indeed use strcmp() on that system, but the test program incorrectly thought it was missing.
Buggy tests are rare on the mainstream platforms autoconf is targeted at (notably Linux varieties, but also the major Unix distributions), and are most often a result of running a test on a compiler or platform that isn't widely tested. For instance, gcc on UnixWare didn't trigger the above bug; only the compiler that came with the system's native development package did. Often, the easiest thing to do is simply to comment out the relevant test in configure, and set the variable in question directly.
Compiler not really working
A particularly pernicious variation occurs when the compiler flags selected in the early phases of configure are able to link executables, but the resulting executables won't run. This can cause tests to fail gratuitously. For instance, if the linker command you're using is wrong, you might get programs that link correctly but don't run. As of this writing, a configure script can fail to spot this, so only those tests that require the target program to be run will report failure. This can be pretty surprising to debug, but the config.log script will make clear what went wrong. For instance, on one test system, I got this output:
Listing 5. Test config.log output
|
What really went wrong is that the compiler needed a separate flag to tell it that /usr/X11R6/lib needed to be in the list of directories to search at runtime for dynamically-linked libraries. However, this was the first test that actually ran the compiled test program instead of stopping once the program was compiled successfully. This is a pretty subtle problem.
The solution, on this system, was to add
-Wl,-R/usr/X11R6/lib
to the CFLAGS variable. The command line:
$ CFLAGS="-Wl,-R/usr/X11R6/lib" ./configure
allowed configure to run this test correctly.
This is especially pernicious for cross-compiling, since you probably can't run an executable actually created with the cross compiler. More recent versions of autoconf try very hard to avoid tests that require the test program to actually get executed.
Finding missing libraries and includes
Another common problem you're likely to find with configure scripts is the case where a given package is installed in an unlikely place, and configure can't find it. A good configure script will often allow you to specify the locations of files that are necessary, but that may be installed in unusual locations. For instance, many configure scripts provide a standard way to tell the script where to look for X libraries:
Listing 6. Finding X libraries
|
If that doesn't work, you can always try the sheer brute force method: specify the necessary compiler flags as part of your CC environment variable, or as part of the CFLAGS environment variable.
Miscellaneous tricks
One workaround, if the developer has provided the configure.in file that autoconf uses to generate the configure script, is to run the newest version of autoconf. It may just work, but even if it doesn't work perfectly, it may well resolve a few problems. The goal here is to update the specific tests used; it may be simply a bug in an older version of configure that is causing the problem. With that in mind, if you're the developer in this equation, be sure to distribute the configure.in file you used.
If you're doing a lot of iteration on tweaking the arguments you pass to configure, and your shell's command-line editing isn't good enough for you, make a wrapper script that calls configure with appropriate arguments. After a bit of tweaking and a few failed tests worked around, your script might look like this:
|
Having the script in one place is a lot more convenient than typing something like that on the command line over and over — and you can refer to it later, or mail someone a copy of it.
Developing robust configure scripts
An ounce of prevention is worth a pound of cure. The best way to make a configure script work is to make sure that, when you're generating one, you do the best you can to make it unlikely to fail.
The most important thing when trying to build a robust configure script is simple. Never, ever, test for anything if you don't really need to. Do not test for sizeof(char); since the sizeof operator in C returns the number of char-sized objects used to hold something, sizeof(char) is always 1 (even for machines where char is more than 8 bits). In most cases, there is no reason to test for access to functions that have been part of ANSI/ISO C since the 1989 version of the standard came out, or for availability of the standard C headers. Worse still are tests for non-standard features when a standard one exists. Don't test for the availability of malloc(), use
In many cases, simply removing a dependency on an obscure feature is more reliable than testing extensively to figure out which one to use. Portable programs are not as hard to write as they were ten years ago.
Finally, try to make sure you're using the most current version of autoconf. Bugs get fixed pretty aggressively; it's very likely that an older version of autoconf will have bugs that have been removed in newer versions.
- For more information, see the
autoconfhome page. - There are very detailed resources available for Creating Automatic Configuration Scripts.
- GNU.org offers advice on Writing configure.ac and Making
configureScripts. - Learn more than you ever knew you wanted to about GNU Make. You'll also find info on Makefile basics, writing proper documentation, and much more at GNU.org.
- Learn more about cross-compiling from Christian Berger.
- IBM developerWorks explores cross-compilation in the article, “Setting up a cross-compilation development environment for the Sharp Zaurus handheld.”
- Erik Welsh's Bookmarks for Cross Compiling is a good place to start to find more specific information.
- Learn how to convert an existing C program or module into a cross-platform shared library in this IBM developerWorks tutorial.
- Trying to write portable code? Follow the 10 Commandments for C Programmers.
- Red Hat has a section in Autobook on Writing Portable C with GNU autotools.
- Speaking of Red Hat, learn how to make an even more convenient installer with the IBM developerWorks article “Packaging software with RPM.”
- If you are new to Linux, learn about installing software in “Part 9 of the Windows-to-Linux roadmap.”
- You'll find rules and download instructions for Angband, the game Peter mentions in this article, at thangorodrim.net. Angband is a Roguelike game.
|
|
 About the author: Peter Seebach still remembers trying to figure out whether an Amiga was best represented with
About the author: Peter Seebach still remembers trying to figure out whether an Amiga was best represented with First published by IBM developerWorks. Reproduced by LinuxDevices.com with permission.
This article was originally published on LinuxDevices.com and has been donated to the open source community by QuinStreet Inc. Please visit LinuxToday.com for up-to-date news and articles about Linux and open source.