EJLonline: In-Memory Database Systems
Sep 1, 2002 — by LinuxDevices Staff — from the LinuxDevices Archive — viewsIMDSes are especially useful for embedded development, where every saved process shrinks the footprint and the bottom line.
Growth in intelligent connected devices is soaring. Whether in the home, the pocket or built into industrial communications and transportation systems, such gear has evolved to include powerful CPUs and sophisticated embedded systems software. One type of software increasingly seen within such devices is the database management system (DBMS). While familiar on desktops and servers, databases are a recent arrival to embedded systems. Like any organism dropped into a new environment, databases must evolve. A new type of DBMS, the in-memory database system (IMDS), represents the latest step in DBMSes' adaptation to embedded systems.
Why are embedded systems developers turning to databases? Market competition requires that devices like set-top boxes, network switches and consumer electronics become “smarter”. To support expanding feature sets, applications generally must manage larger volumes of more complex data. As a result, many device developers find they are outgrowing self-developed data management solutions, which can be especially difficult to maintain and extend as application requirements increase.
In addition, the trend toward standard, commercial off-the-shelf (COTS) embedded operating systems–and away from a fragmented environment of many proprietary systems–promotes the availability of databases. The emergence of a widely used OS such as embedded Linux creates a user community, which in turn spurs development (both commercially and noncommercially) of databases and other tools to enhance the platform.
So device developers are turning to commercial databases, but existing embedded DBMS software has not provided the ideal fit. Embedded databases emerged well over a decade ago to support business systems, with features including complex caching logic and abnormal termination recovery. But on a device, within a set-top box or next-generation fax machine, for example, these abilities are often unnecessary and cause the application to exceed available memory and CPU resources.
In addition, traditional databases are built to store data on disk. Disk I/O, as a mechanical process, is tremendously expensive in terms of performance. This often makes traditional databases too slow for embedded systems that require real-time performance.
In-memory databases have emerged specifically to meet the performance needs and resource availability in embedded systems. As the name implies, IMDSes reside entirely in memory–they never go to disk.
So is an IMDS simply a traditional database that's been loaded into memory? That's a fair question because disk I/O elimination is the best-known aspect of this new technology. The capability to create a RAM disk, a filesystem in memory, is built into Linux. Wouldn't deploying a well-known database system, such as MySQL or even Oracle, on such a disk provide the same benefits?
In fact, IMDSes are considerably different beasts from their embedded DBMS cousins. Compared to traditional databases, IMDSes are less complex. Beyond the elimination of disk I/O, in-memory database systems have fewer moving parts or interacting processes. This leads to greater frugality in RAM and CPU use and faster overall responsiveness than can be achieved by deploying a traditional DBMS in memory. An understanding of what's been designed out of, or significantly modified in, IMDSes is important in deciding whether such a technology suits a given project. Three key differences are described below.
Caching
Due to the performance drain caused by physical disk access, virtually all traditional DBMS software incorporates caching to keep the most recently used portions of the database in memory. Caching logic includes cache synchronization, which makes sure that an image of a database page in cache is consistent with the physical database page on disk. Cache lookup also is included, which determines if data requested by the application is in cache; if not, the page is retrieved and added to the cache for future reference.
These processes play out regardless of whether a disk-based DBMS is deployed in memory, such as on a RAM disk. By eliminating caching, IMDS databases remove a significant source of complexity and performance overhead, and in the process slim down the RAM and CPU requirements of the IMDS.
Data-Transfer Overhead
Consider the handoffs required for an application to read a piece of data from a traditional disk-based database, modify it and write that piece of data back to the database. The process is illustrated in Figure 1.
- The application requests the data item from the database runtime through the database API.
- The database runtime instructs the filesystem to retrieve the data from the physical media.
- The filesystem makes a copy of the data for its cache and passes another copy to the database.
- The database keeps one copy in its cache and passes another copy to the application.
- The application modifies its copy and passes it back to the database through the database API.
- The database runtime copies the modified data item back to database cache.
- The copy in the database cache is eventually written to the filesystem, where it is updated in the filesystem cache.
- Finally, the data is written back to the physical media.
These steps cannot be turned off in a traditional database, even when processing takes place entirely within memory. And this simplified scenario doesn't account for the additional copies and transfers required for transaction logging!
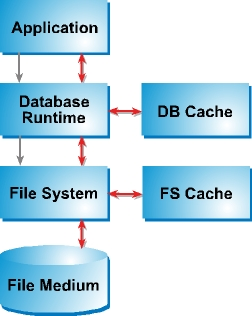
Figure 1. Data flow in a traditional DBMS. Red lines represent data transfer. Gray lines represent message path.
In contrast, an in-memory database system entails little or no data transfer. The application may make copies of the data in local program variables, but it is not required. Instead, the IMDS gives the application a pointer that refers directly to the data item in the database, enabling the application to work with the data directly. The data is still protected because the pointer is used only through the database API, which insures that it is used properly. Elimination of multiple data transfers streamlines processing. Cutting multiple data copies reduces memory consumption, and the simplicity of this design makes for greater reliability.
Transaction Processing
In the event of a catastrophic failure, such as loss of power, a disk-based database recovers by committing complete transactions or rolling back partial transactions from log files when the system restarts. Disk-based databases are hard-wired to keep transaction logs, to flush transaction log files and to cache to disk after transactions are committed.
Main memory databases also provide transactional integrity. To do this, the IMDS maintains a before image of the objects that are updated or deleted and a list of database pages added during a transaction. When the application commits the transaction, the memory for before images and page references returns to the memory pool (a fast and efficient process). If an in-memory database must abort a transaction (for example, if the inbound data stream is interrupted), the before images are restored to the database and the newly inserted pages are returned to the memory.
In the event of catastrophic failure, the in-memory database image is lost. This is a major difference from disk-based databases. If the system is turned off, the IMDS is reprovisioned upon restart. Consequently, there is no reason to keep transaction log files, and another complex, memory-intensive task is eliminated from the IMDS.
This functionality may not suit every application, but in the embedded systems arena, examples abound of applications with data stores that can be easily replenished in real time. These include a program guide application in a set-top box that downloads from a satellite or cable head-end, a wireless access point provisioned by a server upstream or an IP routing table that is repopulated as protocols discover network topology. Developers of such systems gladly limit the scope of transaction processing in exchange for superior performance and a smaller footprint.
This does not preclude the use of saved local data. With an IMDS, the application can open a stream (a socket, pipe or a file pointer) and instruct the database runtime to read or write a database image from or to the stream. This feature could be used to create and maintain boot-stage data, i.e., an initial starting point for the database. The other end of the stream can be a pipe to another process or a filesystem pointer (any filesystem, whether it's magnetic, optical or Flash).
Application Scenario: IP Routers
Where and how can IMDS technology make a difference? While in-memory databases have cropped up in various application settings, the following scenario, involving embedded software in the most common internet infrastructure device–the IP router, offers an idea of the problems this technology can address.
Modern IP routers incorporate routing table management (RTM) software that accomplishes the core task of determining the next hop for data packets on the Internet and other networks. Routing protocols continuously monitor available routes and the status of other routing devices, then update the device's routing table with current data.
These routing tables typically exist as proprietary outgrowths of the RTM software. This solution is one of the principal challenges in developing next-generation routers. As device functionality increases, routing table management presents a significant programming bottleneck. Lacking support for the complex data types and multiple access methods that are hallmarks of databases, self-developed routing table management (RTM) structures provide a limited toolset.
In addition, like any data management solution that is hard-wired to the application it supports, routing tables encounter difficulties in extensibility and reliability. Changes made to the data management code reverberate through the entire RTM structure, causing unwanted surprises and adding to QA cycles. Scalability is also an issue: self-developed data management that works well for a given task often stumbles when the intensity of use is ratcheted up. The result is that while the Internet's growth requires rapid advances in routing technology, this device evolution is slowed by software architecture that has outlived its usefulness.
Under such conditions, using a database would seem to be a no-brainer. But deploying a traditional DBMS within an IP router is problematic. Real-time internet address lookups won't accommodate the latency required to go to disk and perform the caching, transaction logging and other processes that are part and parcel of disk-based DBMSes.
In addition, imposing a large database footprint within the router necessitates more RAM and a more powerful CPU. This adds to the overall device cost, and the market for routers is price-competitive. Even a slightly lower per-unit price increases the manufacturer's market share, and a lower per-unit cost drops right to the bottom line. Software that saves RAM, or requires a less expensive processor, can determine product success.
The emergence of in-memory databases allows the application of DBMS technology to many embedded systems. For developers of embedded systems, proven database technology provides benefits including optimized access methods and data layout, standard and simplified navigation methods, built-in concurrency and data integrity mechanisms, and improved flexibility and fault tolerance. Adoption of this new breed of DBMS simplifies embedded system development while addressing growing software complexity and ensuring high availability and reliability.
 Steve Graves is president and cofounder of McObject, developer of the eXtremeDB in-memory database system. As president of Raima Corporation, he helped pioneer the use of DBMS technology in embedded systems, working closely with companies in building database-enabled intelligent devices. A database industry veteran, Graves has held executive-level engineering, consulting and sales/marketing positions at several public and private technology companies.
Steve Graves is president and cofounder of McObject, developer of the eXtremeDB in-memory database system. As president of Raima Corporation, he helped pioneer the use of DBMS technology in embedded systems, working closely with companies in building database-enabled intelligent devices. A database industry veteran, Graves has held executive-level engineering, consulting and sales/marketing positions at several public and private technology companies.
Copyright © 2002 Specialized Systems Consultants, Inc., publishers of the monthly magazine Linux Journal. All rights reserved. Embedded Linux Journal Online is a cooperative project of Linux Journal and LinuxDevices.com.
This article was originally published on LinuxDevices.com and has been donated to the open source community by QuinStreet Inc. Please visit LinuxToday.com for up-to-date news and articles about Linux and open source.