Demystifying embedded code storage
May 9, 2008 — by LinuxDevices Staff — from the LinuxDevices Archive — 6 viewsForeword — This whitepaper compares four approaches to storing program code on flash memory, including eXecute-in-place (XIP), fully shadowed, demand paging, and “balanced” XIP. It concludes that the latter approach can save Flash and RAM while lowering launch time, especially when used with the AXFS (advanced XIP filing system).
The paper was authored by three engineers at Numonyx, an Intel and STMicroelectronics joint venture devoted to flash memory. In particular, Numonyx aims to commercialize the phase-change memory jointly developed by Intel and STM.
The paper's authors also contribute to the AXFS filesystem project, which is championed in the paper. Enjoy . . . !
Optimizing for lower cost and higher performance through balanced XIP
Introduction
Embedded system[1] designers have a variety of code execution methods to choose from: eXecute-In-Place[2] (XIP), Fully Shadowed[3] and Demand Paging[4]. Using the best method is the key for a cost-effective solution. Each method has different implications in terms of RAM and Flash usage which directly affect the cost of the system. By choosing the best solution, the designer can realize optimal speed and chip size while reducing the Bill of Materials (BOM). This paper will explore a new type of code execution called Balanced XIP. Balanced XIP combines XIP and Demand Paging to achieve a flexible solution that can be optimized for the greatest overall performance and Flash/RAM usage to accommodate continuously changing requirements.
Techniques and approaches
Many factors are involved with determining the code execution method for a system; BOM cost, processor features, OS capability, etc. A system may not support paging if the processor lacks a Memory Management Unit[5]. Most RTOS[6] do not have the dynamic memory management system needed for Demand Paging. Therefore many RTOS designs are limited to either Fully Shadowed or Execute-In-Place. If the hardware supports it, a full-featured operating system may be used to allow for a Demand Paging or a Balanced XIP approach.
Execute-In-Place
With Execute-In-Place (XIP), code is executed directly from the Flash memory where it is being stored. Only volatile data is stored in RAM. The XIP method of code storage is not possible on conventional NAND[7] Flash, thus NOR[8] Flash is used. Designers who choose to use a NAND implementation often use the Fully Shadowed code storage method.
Fully shadowed
A Fully Shadowed system stores all system code and data to Flash, which is copied to RAM by the boot loader. At boot up, the entire code image must be transferred to RAM before code execution can begin. Thus, as the code image grows in size the system boot-time increases. The RAM usage of the Fully Shadowed technique goes beyond that of the XIP system since the entire code image must be stored in RAM. The increased RAM requirement increases the power consumption of the system and adds to the BOM.
Demand paging
Instead of copying all of the stored code into RAM (Fully Shadowed method), paging methods only copy some code to RAM from Flash. Some paging methods copy entire applications into RAM. Demand Paging systems copy pages as required into RAM and retire pages no longer in use. Nearly all PC operating systems use Demand Paging, selecting pages of memory on the hard-drive and copying them into RAM. The Demand Paged execution of code reduces the RAM usage compared with the Fully Shadowed technique since the entire system image does not need to be transferred to RAM. In embedded systems with a Demand Paging OS, such as Linux, the code pages on Flash are usually stored in a compressed state which reduces the Flash utilization.
The RAM savings compared to Fully Shadowed is very dependent on the system�s usage model. If the system is to run multiple applications simultaneously, then more code needs to be resident in RAM. This results in similar RAM usage as in the Fully Shadowed System. If a small amount of RAM is dedicated for Demand Paging then programs will face extra latency as the OS continuously swaps out pages. Thus, performance is tied to the abundance of system RAM and allocation of available RAM for paging.
Balanced XIP
Demand Paging and XIP can be used together to balance the RAM usage and Flash usage. This gives the designer the flexibility to choose code execution from Flash or RAM. A Balanced XIP system can be created by shifting the code memory between Flash and RAM. The goal of balancing system is to achieve an optimal fit to a reduced memory footprint, the smallest RAM/Flash combination.
Comparing code storage methods
Compression
Code compression benefits embedded systems by reducing the amount of Flash required for code storage. Fully Shadowed and Demand Paged architectures can implement compression. While many Demand Paged architectures use compression, few Fully Shadowed systems use compression to simplify the system implementation. XIP architectures cannot implement compression because processors cannot execute compressed code directly. Compressed code must be uncompressed before it can be executed. Demand Paged architectures that implement compression typically compress on a block size that is a multiple of the page size, typically 4KB. This way only a single page or a few pages need to be decompressed, when a page of code is required. For a Balanced XIP system, the code that is executed from Flash must be uncompressed; the code that is executed from RAM should be compressed in Flash to minimize Flash usage.
RAM and flash usage
Consider a design with 24MB of executable code. A Fully Shadowed approach would use 24MB of RAM (ignoring for the moment additional RAM needed for scratchpad data) and 24MB of Flash for code. With an XIP approach, the system would use 24MB of Flash, and 0MB of RAM to store the code. A Demand Paged system, with compression (approximately 50percent), would use about 12MB of Flash and some amount less than 24MB of RAM, depending on the usage model, performance requirements, and the nature of the code itself. Assuming the Demand Paged code only requires 12MB of RAM for code, a Balanced XIP system would use between 12MB and 24MB of Flash because it requires more Flash than Demand Paging and yet less than XIP. As for RAM, a Balanced XIP system would require between 0 and 12MB for code because it requires less RAM than the Demand Paging example, but more than XIP.
The Balanced XIP model gives the designer the most flexibility to create a system that can fit into standard 2n memory chip sizes. Given the example design above and assuming the system requires 8MB of RAM for volatile data (working space), Figure 1 illustrates the memory chip sizes each architecture would require. Because of the assumed 12MB of RAM required for code in the Demand Paging example, the system would require 20MB of RAM. But, the system designer would probably design in a 32MB RAM chip and burden the cost and power budget of the design with 12MB of RAM. The amount of RAM required for a Demand Paging system is flexible, but the tradeoff is performance and power consumption.
| Architecture | Flash | RAM | ||
|---|---|---|---|---|
| Requirement | Real/Chip Size | Requirement | Real/Chip Size | |
| Fully Shadowed | 24MB | 32MB | 24MB+8MB | 32MB |
| XIP | 24MB | 32MB| 0MB+8MB |
8MB |
|
| Demand Paging | 12MB | 16MB | 12MB+8MB | 32MB |
| Balanced XIP | 16MB | 16MB | 4MB+8MB | 16MB |
Fig. 1 — RAM and Flash implication of various code storage architectures
| Architecture | RAM Usage | Flash Usage | NOR Flash | NAND Flash | Compression | Boot Time | App Launch |
|---|---|---|---|---|---|---|---|
| Fully Shadowed | – | – | x | x | x | – | – |
| XIP | ++ | – | x | n/a | n/a | + | + |
| Demand Paged | + | + | x | x | x | – | – |
| Balanced XIP | ++ | + | x | n/a | x | + | + |
Figure 2. Comparison of Solutions
Perhaps this Demand Paged design could be squeezed into a 16MB RAM chip, but with reduced performance. However, there are 4MB of Flash not used in the Demand Paged example. This extra Flash could be used to balance this system. Assuming a 50percent compression ratio, 4MB of previously compressed code can be switched to 8MB of XIP/uncompressed Flash, adding 4MB to the Flash required. But, in doing so the RAM required is reduced by 8MB. Now this Balanced system fits into a reduced memory footprint of 16MB of Flash and 16MB of RAM. Thus, the Balanced XIP system has the smallest memory subsystem requirements resulting in lowest cost.
Choosing which code to XIP and which to compress is the key to creating a properly Balanced XIP system. Executable code that is seldom used is best left stored in a compressed state to save Flash. Often used code can be executed in place from Flash to save RAM. In a Demand Paging architecture, consistently used code would always be in RAM. Assuming 50percent compression with a 4KB page size, storing a page of often used code compressed uses 2KB of Flash and uses 4KB of RAM. Storing this page uncompressed/XIP would use 4KB of Flash, but no RAM. Compared to compressed Demand Paging, XIP uses more Flash, but saves twice that amount in RAM. Placing these often executed pages in Flash maximizes available RAM (for other system uses), minimizes application launch time and optimizes Flash usage by compressing unused or infrequently used applications pages.
Performance
Code performance is often a concern when choosing a code storage method. RAM read speeds are typically faster than Flash memory. NOR Flash has similar, but worse latency and bandwidth compared to RAM. While NAND Flash has very long read latency and less bandwidth than both NOR and RAM. NAND cannot be used for XIP because of these long latencies. It is often assumed that code execution from NOR Flash would be slower than code execution from RAM. However, processor instruction caches hide the differences in read speed that may exist between RAM and NOR. Paging architectures have latencies associated with interrupting the system, finding the code needed, decompressing it, and so forth. This latency occurs more often as a Demand Paged system becomes RAM constrained. Using XIP can increase the launch speed and in some cases the runtime performance when compared to a Demand Paged system because XIP/uncompressed code will not have the latencies of Demand Paged/compressed code. These factors make it difficult to judge what the performance differences of each code execution method will be.
Real world example
Tested configurations
A production multimedia cellular phone, based on Linux OS, was used to measure the results provided in the following sections. The phone is designed with both gaming and video capabilities. The platform is based on a Marvell PXA270 Xscale processor running at a frequency of 297MHz. The memory subsystem contains 48MB of total RAM and 96MB of total Flash. The PXA270 processor has a 32kB internal instruction and data caches with each cache line consisting of 32 bytes.
The test results compare the 3 different configurations using the same test phone: Demand Paged vs. XIP vs. Balanced XIP. Analysis was done specifically on memory utilization and performance.
Test results
Figure 3 is a summary of the various code storage solutions tested on the platform. The original configuration (demand paging) required 40MB of RAM for the phone to perform. The utilization of code compression allowed for the total code size to be only 35MB of the total 96MB of Flash. This leaves the remaining 61MB for user storage such as preloaded files and additional music or movie downloads.

Figure 3. Code storage solutions
(Click to enlarge)
The XIP configuration requires that all code executes directly from Flash, making code compression impossible. Because of this, only 29 MB of the Flash memory will remain for user storage. Typically, this is not enough space to store all the required phone data, as well as give the user adequate space to store their own personal files. The advantage of the XIP configuration, though, is that direct code execution from the Flash alleviates the demand on RAM for code storage. Only 22MB of RAM is required.
In the Balanced XIP solution, most commonly accessed code regions are directly executed from Flash, while the remainder is paged on demand. While using only 6MB more RAM than the XIP configuration, the code balanced configuration allows for 53MB of user storage space, and 83percent increase in available Flash user space for personal data.
Figure 4 demonstrates the code balancing done on the test platform. In the Demand Paged system, 16MB were selected from the page cache as the most commonly accessed code areas. This uncompressed code represents 8MB of compressed code in Flash. In the Balanced XIP configuration, the selected uncompressed code is now stored and directly executed from Flash, thus also alleviating the demand on the RAM.
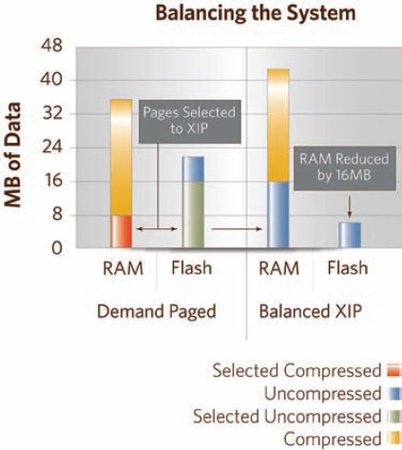
Figure 4. Balancing the system
(Click to enlarge)
One key advantage of the Balanced XIP architecture in the test phone design is that the designer was able to maintain enough user storage space while keeping the RAM requirements below 32MB (see Figure 3). This 32MB boundary is critical to the cost of the overall memory subsystem because otherwise, the designer would be forced to use either a second RAM die (16MB) or to purchase the next larger monolithic die (64MB). The reduced RAM array size also leads to power savings in hand-held devices when the phone enters a low-power state. Using half the RAM leads to refreshing half as much RAM. Standby battery life is a key selling point to mobile device sales.
Performance analysis
On a Demand Paged implementation, libraries and executable code become available when a page fault occurs, at which time the page is copied into RAM. As applications run, the page faults slow down the system by fetching and decompressing the pages for every page fault. In a completely XIP implementation, the applications execute directly from the Flash, eliminating wasted time spent fetching and decompressing pages into RAM; the result is a performance advantage during application launch.
Conversely, it is believed that the Demand Page system has better application runtime performance because the code is running from RAM, making Demand Paging better for the user's runtime experience. On the contrary, the runtime performance of an XIP system is the same as a Deman Page based system because the majority of code will run from the processor's cache. As a result, the Balanced XIP solution gives the best user experience because of the faster load time and same runtime performance.
A second investigation was conducted to measure boot and application performance between a Balanced XIP system and a NAND Demand Paged system. The analysis was performed on a Marvell PXA27x Development System running Linux 2.6.14. Applications were stored in a Linear XIP CRAMFS filing system on the Balanced XIP system and in a JFFS2 filing system on the Demand Paged system. Figure 5 shows the measured boot and application launch times for Balanced XIP and Demand Page system. The launch time for both the first-person shooter Quake[9] and Konqueror Web Browser was slower on the Demand Page system than the Balanced XIP implementation, while runtime performance of the applications were equivalent on both systems.
Balanced execute-in-place filing system
There are two XIP-enabled Linux filing systems that can be used for a Balanced XIP implementation: Linear XIP CRAMFS and AXFS. The Linear XIP CRAMFS decompresses files on a file-by-file basis, whereas AXFS decompresses files on a page-by-page basis offering more optimal Flash usage.
Linear XIP CRAMFS
Linus Torvalds originally wrote CRAMFS as a compressed read-only filing system to enable bootable floppies to install the Linux operating system on PCs. Over time, CRAMFS was modified for use in embedded systems. The Linear XIP variant adds the ability to specify each file to be stored on Flash as compressed (Demand Paged) and uncompressed (XIP). When a file is marked to be XIP all of the pages of the file are stored uncompressed contiguously in Flash. When the XIP file is requested to load, all of the page addresses are directly mapped in the memory map. Alternatively, the compressed Demand Paged file will load each page individually when a page fault occurs. During the page fault, the handler must uncompress the page into RAM.
To create a Balanced XIP file system image with Linear CRAMFS, one must determine the frequency of the usage of executables and libraries within a use case. The frequently used files can then be Executed-In-Place for the greatest RAM savings. This is not a difficult task with publicly available tools, such as RAM Usage Scan Tool (RAMUST), showing which files are in the virtual memory map and which ranges within each file are mapped into the system. The Compressed Filing System Size Tool (CFSST) profiles a filing system by listing the compressed and uncompressed size of all files.
Advanced XIP filing system
To improve the Balanced XIP solution, a new filing system was created to replace Linear XIP CRAMFS. The limitation of Linear XIP CRAMFS is that all the pages within an application are either XIP or all compressed Demand Paged. Thus, the granularity to balance the code is limited to entire application/library and not individual pages within a file. Just as in an entire code image only some files are used, within an application some pages are infrequently or never used. Therefore, storing these pages uncompressed/XIP expands the filing system image with no improvement to RAM savings.
Advanced XIP Filing System (AXFS) is a read-only filing system that has the ability to store individual pages in a file uncompressed/XIP or compressed/Demand Paged. AXFS Filing system has a built-in profiling tool to determine which pages should be XIP and which should be Demand Paged. Profiling the system is as easy as turning on system profiling tools and running a target-use scenario (such as turning the phone on, watching a movie, and placing/receiving a phone call). Pages that are infrequently called under the primary use cases are stored compressed. Pages that are often called or associated with key applications (using the most RAM) are stored uncompressed to remove the burden of their RAM usage from the system.
| Technique | Boot | Quake | Browser |
|---|---|---|---|
| Balanced XIP | 32.2s | 20.0s | 2.6s |
| Demand Paged | 71.6s | 26.7s | 2.9s |
| Balanced XIP faster by | 2.2x | 1.3x | 1.5x |
Figure 5. Boot and Application Launch Time
Conclusion
By combining the positive characteristics of XIP and Demand Paging, Balanced XIP systems offer a very optimal solution that provides performance and cost advantages. This technique offers a reduction in Flash usage over a purely XIP system by keeping the rarely used code in a compressed form in Flash. Additionally, this process achieves a reduction in RAM size compared to a Fully Shadowed or Demand paged system by maintaining much of the commonly used code pages decompressed in Flash. Balanced XIP allows a quick boot sequence and faster application launch time by removing the latency involved in copying pages to RAM. The benefits of RAM reduction and decreased boot/launch time make this technique better than the Demand Page method.
Sources
- Acknowledgements
Linear and XIP Linear CRAMFS primary contributors are Shane Nay and Robert Leslie from MontaVista and others from Agenda VR. Linear CRAMFS is an open source community effort. AXFS primary contributors are Eric Anderson, Jared Hulbert, Sujaya Srinivasan and Justin Treon from Numonyx. AXFS is an open source community effort.
- Tools and sources
- CRAMFS
- Advanced XIP filing system
- Quake
- References
CE Linux Forum; “Application XIP“
Wikipedia; “Embedded system“
Yaghmour, Karim; Building Embedded Linux System; O'Reilly Publishing; April 2003
- Terminology
[1] Embedded System: A special-purpose system in which the computer is completely encapsulated by the device it controls; e.g. an ATM, router, or cell phones. Handheld computers or PDAs are generally considered embedded devices because of the nature of their hardware design, even though they are more expandable in software terms. This line of definition continues to blur as devices expand in functionality.
[2] Execute-In-Place (XIP): The code is executed directly from the storage media thus bypassing volatile memory.
[3] Fully Shadowed: A type of Store and Download method, this technique stores all system code and data in a mass which is moved to RAM by the boot loader.
[4] Demand Paging: A version of a Store and Download method where information is stored, but not executed from a Flash on a page-by-page basis. The pages in use are copied into the volatile memory where execution takes place from volatile memory.
[5] Memory Management Unit (MMU): A category of computer components responsible for handling memory access requests such as translating virtual addresses to physical addresses.
[6] RTOS: A Real Time Operating System (RTOS) is applicable for real-time applications. It allows for the execution of real time events. Some examples of this include Nucleus* from Accelerated Technology, VxWorks* from Wind River, etc.
[7] NAND Flash: Non-volatile storage technology consisting of serial alignment of the transistors and uses tunnel injection for programming. In comparison to NOR Flash, the NAND architecture allows for faster contiguous data writes due to a faster erase speed. Best used for user data storage due to reliability.
[8] NOR Flash: Non-volatile storage technology consisting of parallel alignment of the transistors and uses hot electron injection for programming. In comparison to NAND Flash the architecture allows for faster random reads and slower block writes. Best used for code storage.
[9] Quake: 3D first-person shooter game originally released by id Software in June 22, 1996 for the desktop PC market. The game has been used as a 3D benchmark since its release now used in the handheld market as well as the desktop market. Our testing used a Linux port called SDL Quake.
Copyright Numonyx, 2008, all rights reserved. Reprinted with permission by LinuxDevices.com.
This article was originally published on LinuxDevices.com and has been donated to the open source community by QuinStreet Inc. Please visit LinuxToday.com for up-to-date news and articles about Linux and open source.