Article: Fundamentals of Real-time Linux Software Design
Dec 15, 2000 — by Rick Lehrbaum — from the LinuxDevices Archive — 5 viewsA simple model of real-time applications
A typical real-time application involves a task performing some operation within a deadline. For example: storing some data, or updating a display. The task often is designed to repeat such activities ad infinitum, beginning each iteration at the occurrence of a hardware interrupt. This interrupt may be caused by a human clicking a button, a temperature reading, data from a visual sensor, or innumerable other possibilities.
In this article, we'll discuss Linux, with respect to aiding such systems. For starters, let's assume that our real-time system involves the following:
- One or more user level tasks
- An interrupt handler
- A single CPU
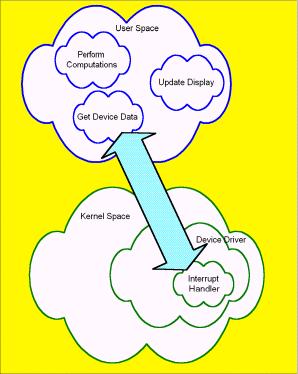
Figure 1: User Space vs. Kernel Space
In Figure 1, we see a simple diagram that illustrates a representative real-time application. We see that in kernel space we have a device driver and within that device driver we have our interrupt handler. We shall see that activities within the kernel, such as the performance of our interrupt handler, are critical to real-time performance. There are additional kernel issues as well, such as the behavior of the rest of the device drivers, the kernel's policy toward disabling interrupts, and the kernel's preemption model although they aren't represented in the diagram.
In some approaches to real-time with Linux, we'll see that in addition to traditional device drivers, more sophisticated processing by the real-time application may be relegated to kernel space. This, for example, is the approach of both RTLinux and RTAI.
Even with RTLinux/RTAI, it is generally the case that a real-time application will have tasks executing within user space. The issue then becomes the reliability of their performance. The behavior of all user space programs, including daemons, may be important. In particular, if any user task other than your time-critical real-time task is making system calls, then that may delay your task.
In the example illustrated in Figure 1, we show three user space tasks: “Get Device Data,” “Perform Computations,” and “Update Display.” These may be implemented as either POSIX Threads or Linux processes. Together, they represent our prototypical real-time system. A possible scenario for their operation is (simplified) . . .
- Our “real-time” device asserts an interrupt indicating that it has data to deliver;
- The device driver interrupt handler is run;
- The interrupt handler copies data from the device to user space and wakes up our Get Device Data task;
- Our user space task (Get Device Data) runs, preprocesses the data, and notifies Perform Computations that data is available;
- Perform Computations runs, creating some cooked data, and then it notifies Update Display that data is available;
- Update Display shows a new sequence of lights, frames of graphics, or whatever.
Using timers
Rather than basing our system's real-time operation on interrupts from an outside device, we could instead use internal system timers to schedule an activity. However, the normal resolution of timers in Linux is 10 milliseconds, which tends to be far too slow for most real-time applications.
Alternatives exist that improve Linux kernel timer resolution to approximately 1 microsecond. Solutions to do this are available from the open source projects KURT and RED-Linux, as well as from several real-time Linux vendors including REDSonic and TimeSys. With timers, it's also common to have specifications that limit jitter. That is, the timer tick must happen on time; it must come neither too late, nor too early — it must come regularly.
A typical real-time event timeline
In Figure 2, we represent a typical real-time event as a timeline. In the illustration, we have divided up the time period for an iteration of work, from when the interrupt is asserted until the task completes, into four segments. In the real-time event timeline, we have identified five milestones that delineate the four segments of the timeline . . .
- Interrupt asserted — our device generates an interrupt;
- Handler started — the handler for the interrupt from our device starts running;
- Task put on run queue — our task is awakened, and placed in the run queue;
- Task starts running — our task actually gets the CPU and begins processing. Prior to this occurring, our task may have been blocked in the kernel, perhaps due to a read call to our device, waiting to be notified that new data had arrived;
- Task iteration completed — finally, our task actually completes processing its collection of data.
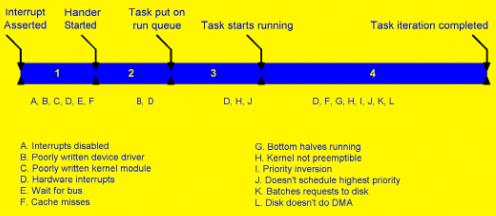
Figure 2: A typical real-time event timeline
In this example, we have used Get Device Data as the task represented by the timeline. The timeline will help us to examine the sources of delays in each of the four segments, and to relate the delays to various solutions that are available.
Note, by the way, that the timeline is not drawn to scale. For example, the time for Segment 1 (“Interrupt Asserted” to “Handler Started”) may only 15 uS. This would also represent the time for a task within RTAI or RTLinux to begin, since they are designed to essentially be run at the interrupt level. The time for Segment 2 (“Handler Started” to “Task Put on the Run Queue”) may be much shorter than 15 uS, if the handler written is typical and if the system is not incurring a large number of other interrupts. The time for Segment 3 (“Task put on Run Queue” to “Task Starts Running”) may be quite long — indefinitely long. Here, designing the system to ensure proper priorities, that tasks are locked in memory, etc., is critical. But, other factors, such as the algorithms in the scheduler, may introduce significant delays — perhaps many milliseconds. Finally, the time for Segment 4 (“Task starts running” to “Task Iteration Completed”) depends, of course, on the application code itself. It may also depend on other activities within the system.
Initial observations
This brief overview leads to these two important principles, which we will discuss in more detail later:
- It is critical that no undue delays are introduced in any aspect of your real-time system design;
- Despite the availability of OS features that can theoretically satisfy the real-time performance requirements of your application, meeting those requirements can easily be thwarted by inappropriate software behavior.
In other words, when you design real-time system software, you must responsibly make use of the system's available facilities. This includes all kernel code — i.e. device drivers, the scheduler, the preemption model — as well as the disabling of interrupts. For example, use mlock() to avoid paging. Also, be sure to take into account the behavior of other user space tasks. For example, avoid mechanisms that might result in significant delays due to priority inversion.
Timeline Segment 1: Getting the handler started
The handler typically begins within about 15us on an x86 architecture (often, in less time on other architectures). In the PC architecture, inherent inefficiencies are often among the most important factors.
Let's examine the factors listed in the diagram.
Interrupts disabled; poorly written device driver; poorly written kernel module
Interrupts are disabled to ensure that a handler does not run concurrently with any other code, either in a handler or elsewhere in the kernel, that requires exclusive access to some item of shared data. The Linux kernel also disables interrupts to ensure that the kernel is not reentered until an appropriate time. Measurements indicate that Linux may disable interrupts for periods of 100 milliseconds or more. This means the handler for your real-time device may be delayed by that amount.
Any device driver or kernel module used in your system is capable of disabling interrupts. Well written drivers and, in particular, kernel code may minimize their interrupt off times.
Note that RTLinux and RTAI also disable interrupts. But they do so for extremely short periods, and thus their interrupts-disabled intervals are not significant sources of delay.
Wait for bus; cache misses; other hardware interrupts
Assuming that interrupts were not disabled at the time the interrupt in our example real-time event occurred, the system architecture itself may be the source of the majority of the delay in getting into the interrupt handler. Two such items are: the time to communicate with the device about the interrupt; and the time to bring the code and data for your handler into cache. The speed of communicating with the device may be greatly reduced by a slow bus, such as the ISA bus, which might be busy at the time the interrupt occurs.
The interrupt handler may also be delayed if additional interrupts are received immediately before, or after, the interrupt that summons the handler.
In the case that interrupts are not disabled and the system is not receiving a lot of interrupts, the handler can be expected to start executing within a few 10's of microseconds.
Improving the situation
Since the most important factor in getting your handler started is whether or not interrupts are disabled, it is most important to attack this issue. Here are some options . . .
- Some Linux vendors have analyzed the time intervals where interrupts are disabled, and have improved the situation by rewriting the Linux code;
- You can select device drivers that optimize the system's interrupt behavior;
- Be careful about how long you disable interrupts in your own code;
- Avoid kernel activity at the time when an interrupt may arrive. This is typically done by being careful to avoid having a process make system calls at critical times;
Timeline Segment 2: Waking up your task
Normally this time interval is negligibly small. The interrupt handler should wake up the task. However, if the handler is written poorly, it is conceivable that it may take a longer time than expected to do that. In addition the handler may be interrupted by other interrupts coming into the system.
In general, it is not common for this portion of the timeline to represent an area of significant delay when the other areas are delay free.
Timeline Segment 3: Getting your task running
Just as in every other area of the timeline, hardware interrupts can cause delays. It is common practice to assume hardware interrupts will be sufficiently infrequent that they will represent no real concern. In most circumstances, this assumption is valid.
Linux device drivers are usually designed so that the handler disables interrupts for only a short time. This is accomplished by having longer running code execute in the handler's “bottom half.” A bottom half is kernel code that executes with interrupts enabled. But, since it's kernel code, it will run prior to a user process regaining the CPU. Thus, if a driver schedules considerable bottom half processing, your process may be subject to significant delay.
The issue of kernel preemptibility is particularly important in this segment of the timeline. As you can see on the timeline, our task has been awakened and is ready.
It is possible that when the interrupt came, the kernel may have been in the middle of a system call for another process. As a result, the kernel may have delayed switching to our task.
Measurements indicate that the standard Linux kernel may currently provide maximum latencies on the order of 100 milliseconds without patches to improve the situation (reference). A commonly cited improvement is to use Ingo Molnar's low latency patch. For audio applications, for example, which require approximately 5 mS
latency, Molnar's patches have been found to be satisfactory.
The issue of scheduling is also critical at this point. Just because your task is on the ready queue, doesn't mean it will get the CPU next. You would think that having the highest priority would be sufficient, but that's not necessarily the case. Since Linux is optimized for average system throughput, it may delay switching to a higher priority task. MontaVista, REDSonic, and TimeSys offer improved schedulers that are intended to remedy this situation.
Timeline Segment 4: Keeping your task running quickly
Once your task gets started, you want it to keep running. Making system calls, for example, can lead to delays. As before, hardware interrupts that occur can slow down the task. Programming techniques that avoid cache misses — or, worse still, page faults — may be important. The kernel may have to run interrupt handlers, including bottom halves, instead of your task.
If your task blocks on a resource, like a semaphore or mutex, it may be blocked an indefinite amount of time if the mechanism you've chosen does not avoid priority inversion. Again, if your process gets preempted, it goes back to the beginning of segment three, and may be delayed.
Other aspects of your application are also important, including, such as the methods used by device drivers to work with their devices. For example, a hard disk driver may be optionally configured to use DMA (using the command hdparm). Also, the Linux kernel disk driver is written to batch up disk requests. Thus, your request may be delayed.
Improving the situation
The most important improvements for this segment of the timeline are: use good programming techniques; use synchronization methods that ensure that no priority inversion occurs; and use device drivers that support real-time.
Summary
In this article, we have examined some important issues relating to . . .
- Reliable scheduling
- Preemption in the kernel
- Interrupt disabling
- Priority inversion
- Using existing kernel facilities
- Real-time device drivers
In retrospect, it is evident that while a lot of support is available for achieving real-time performance within a Linux-based system environment, it tends not to be all located in one place. Fortunately, much such support is available as open source.
Author's bio: Kevin Dankwardt is founder and President of K Computing, a Silicon Valley training and consulting firm. He has spent most of the last 9 years designing, developing, and delivering technical training for such subjects as Unix system programming, Linux device drivers, real-time programming, and parallel-programming for various organizations world-wide. He received his Ph.D. in Computer Science, in 1988. He may be contacted at [email protected].
Talkback! Do you have questions or comments on this article? talkback here
This article was originally published on LinuxDevices.com and has been donated to the open source community by QuinStreet Inc. Please visit LinuxToday.com for up-to-date news and articles about Linux and open source.