Article: Inside IBM’s BlueGene/L supercomputer
Dec 3, 2003 — by LinuxDevices Staff — from the LinuxDevices Archive — 10 viewsForeword
A team of computer scientists at IBM and the University of California/Lawrence Livermore Labs have used Linux and embedded System on Chip (SoC) technology to achieve a breakthrough in supercomputer technology expected to radically reduce the size and cost of highly scalable systems, while dramatically increasing performance. A prototype the size of a 30-inch television has already weighed in at number 73 on the Top500 Supercomputer project list, producing two teraFLOPS (trillions of floating point operations per second).
The BlueGene/L “Livermore” system, when completed in late 2004, is expected to scale to 128,000 processors and deliver a theoretical 360 teraFLOPS, all while drawing just 1 MegaWatt of power and taking up a mere half-tennis-court worth of floor space. Cooling demands will also be low, by supercomputing standards.
After the “Livermore” system, the BlueGene team will target a system capable of delivering one petaFLOP — a thousand teraFLOPs, or one quadrillion FLOPs.
“Blue Gene's entry onto the Top500 list marks a fracture in the history of supercomputing — it will revolutionize the way supercomputers and servers are built and broaden the kinds of applications we can run on them,” said William Pulleyblank, director of exploratory server systems, IBM Research.
“We're very excited about the prospects of Blue Gene, because the scale of this machine is unprecedented,” said Mark Seager, principal investigator for ASCI platforms at the Lawrence Livermore National Laboratory. “The scale of the science that we will be able to do is phenomenal.”
Planned applications for BlueGene include explorations of molecular dynamics, and complex simulations.
The role of Linux
According to Manish Gupta, manager of emerging system software at IBM, Linux played a fundamental role in the design of BlueGene/L. “We wanted to provide a familiar Linux-based environment, so we support Linux on the front-end host nodes and service nodes.” The Linux-based host nodes manage user interaction functions, while the Linux-based service nodes provide control and monitoring capabilities.
Linux is also used in I/O nodes, which provide a gigabit Ethernet connection to the outside world for each group of 64 compute nodes, or every 128 processors. Thus, the full BlueGene/L system will have 1024 I/O nodes, which essentially form a Linux cluster. “Thousand-way Linux clusters are becoming fairly standard,” notes Gupta.
The actual compute nodes — the 128,000 processors — do not run Linux, but instead run a very simple operating system written from scratch by the Project's scientists. “The kernels are so simple that, in many cases, the kernel doesn't even handle I/O. The I/O nodes service I/O requests from the application.”
Even the non-Linux compute node kernels, however, were influenced by Linux. “We wanted to provide a familiar system call interface and a subset of the system calls that Linux provides,” says Gupta. “[Programmers] shouldn't have to relearn how to do programming to develop applications for this machine.”
Besides Linux, another open source software component crucial to the project is the BSD-licensed MPI, or message passing interface. MPI is used in the tree network between I/O and compute nodes, and “Provides the power network part of the BlueGene/L architecture,” according to Gupta.
SoC technology simplifies
“In order to scale to hundreds of thousands of processors,” says Gupta, “The approach we took was simplicity.”
System on Chip (SOC) technology integrates most compute node functions — processing, message handling, three levels of on-chip cache, floating point units, routing hardware and more — into a single ASIC (Application Specific Integrated Circuit) built on a 0.13-micron process, with an 11.1-mm die size. Each ASIC contains two PowerPC processors running at 700MHz, with one processor serving mainly for message handling. Each compute node also includes up to 2GB of off-chip RAM shared between processors, but more typically will have 256MB or 512MB, according to Gupta.
Gupta enthuses about BlueGene/L's “torus” network between compute nodes as “A special kind of mesh, where you also have wrap-around connections across boundaries. It requires only connections to nearest neighbors: X+, X-, Y+, Y-, Z+ and Z-. The routing circuitry for sending messages to nearest neighbors is embedded on the ASIC chip, and the connection is basically a wire.”
The simple SoC design, coupled with a low processor clock cycle, results in low power and cooling demands that enable 1024 compute nodes — with 2048 processor cores — to occupy a single rack. The full, 128,000-processor BlueGene/L “Livermore” system will comprise 64 racks.
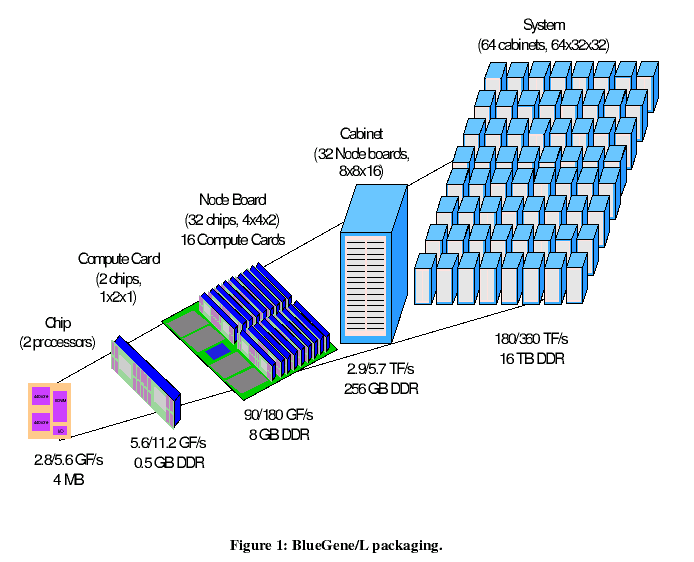
BlueGene/L packaging
(Click for larger view)
The BlueGene/L team got the first of its ASICs in June, and had software running on them within a week. The first BlueGene/L prototype comprises 512 compute nodes, supported by a higher density of I/O nodes than the 64 to 1 ratio targeted for the final “Livermore” system. The prototype also has more off-chip memory.

IBM Research team members inspect the Blue Gene/L prototype.
The final “Livermore” version of BlueGene/L will arrive “before 2005,” according to Gupta, and is expected to top the Top500 list. It will take up just 2,500 square feet, about half the size of a tennis court. Total system memory will be 16 or 32 Terabytes. The file system will be IBM's GPFS filesystem running on a 512-node cluster. It is expected to boot in less than two minutes.

Artist rendition of the BlueGene/L “Livermore” system
(Click for larger view)
— by Henry Kingman, editor, LinuxDevices.com
IBM's 22-page whitepaper, “An overview of the BlueGene/L Supercomputer,” provides more technical details about the project, including:
- Introduction and Background
- System Overview
- System Packaging
- Node Overview
- Torus Network
- Signaling
- Global Trees
- Software Support
- Operating System Architecture
- Programming Models
- Control System
- Autonomic Functions
- Validating the architecture with application programs
- BlueGene science applications development
- References
Click here to read the complete 22-page whitepaper:
(320KB PDF download)
Below, we provide the “Introduction and Background” and “System Overview” sections for you to read while waiting for the download . . .
Introduction and Background
IBM has previously announced a multi-year initiative to build a petaflop scale machine for calculations in the area of life sciences. The BlueGene/L machine is a first step in this program, and is based on a different and more generalized architecture than IBM described in its announcement of the BlueGene program in December of 1999. In particular BlueGene/L is based on an embedded PowerPC processor supporting a large memory space, with standard compilers and message passing environment, albeit with significant additions and modifications to the standard PowerPC system.
Significant progress has been made in recent years mapping numerous compute-intensive applications, many of them grand challenges, to parallel architectures. This has been done to great success largely out of necessity, as it has become clear that currently the only way to achieve teraFLOPS-scale computing is to garner the multiplicative benefits offered by a massively parallel machine. To scale to the next level of parallelism, in which tens of thousands of processors are utilized, the traditional approach of clustering large, fast SMPs will be increasingly limited by power consumption and footprint constraints. For example, to house supercomputers in the 2004 time frame, both the Los Alamos National Laboratory and the Lawrence Livermore National Laboratory have begun constructing buildings with approximately 10x more power and cooling capacity and 2-4x more floor space than existing facilities. In addition, due to the growing gap between the processor cycle times and memory access times, the fastest available processors will typically deliver a continuously decreasing fraction of their peak performance, despite ever more sophisticated memory hierarchies.
The approach taken in BlueGene/L (BG/L) is substantially different. The system is built out of a very large number of nodes, each of which has a relatively modest clock rate. Those nodes present both low power consumption and low cost. The design point of BG/L utilizes IBM PowerPC embedded CMOS processors, embedded DRAM, and system-on-a-chip techniques that allow for integration of all system functions including compute processor, communications processor, 3 cache levels, and multiple high speed interconnection networks with sophisticated routing onto a single ASIC. Because of a relatively modest processor cycle time, the memory is close, in terms of cycles, to the processor. This is also advantageous for power consumption, and enables construction of denser packages in which 1024 compute nodes can be placed within a single rack. Integration of the inter-node communications network functions onto the same ASIC as the processors reduces cost, since the need for a separate, high-speed switch is eliminated. The current design goals of BG/L aim for a scalable supercomputer having up to 65,536 compute nodes and target peak performance of 360 teraFLOPS with extremely cost effective characteristics and low power (~1 MW), cooling (~300 tons) and floor space (<2,500 sq ft) requirements. This peak performance metric is only applicable for applications that can utilize both processors on a node for compute tasks. We anticipate that there will be a large class of problems that will fully utilize one of the two processors in a node with messaging protocol tasks and will therefore not be able to utilize the second processor for computations. For such applications, the target peak performance is 180 teraFLOPS. The BG/L design philosophy has been influenced by other successful massively parallel machines, including QCDSP at Columbia University. In that machine, thousands of processors are connected to form a multidimensional torus with nearest neighbor connections and simple global functions. Columbia University continues to evolve this architecture with their next generation QCDOC machine [QCDOC], which is being developed in cooperation with IBM research. QCDOC will also use a PowerPC processing core in an earlier technology, a simpler floating point unit, and a simpler nearest neighbor network. System Overview
BlueGene/L is a scalable system in which the maximum number of compute nodes assigned to a single parallel job is 216 = 65,536. BlueGene/L is configured as a 64 x 32 x 32 three-dimensional torus of compute nodes. Each node consists of a single ASIC and memory. Each node can support up to 2 GB of local memory; our current plan calls for 9 SDRAM-DDR memory chips with 256 MB of memory per node. The ASIC that powers the nodes is based on IBM's system-on-a-chip technology and incorporates all of the functionality needed by BG/L. The nodes themselves are physically small, with an expected 11.1-mm square die size, allowing for a very high density of processing. The ASIC uses IBM CMOS CU-11 0.13 micron technology and is designed to operate at a target speed of 700 MHz, although the actual clock rate used in BG/L will not be known until chips are available in quantity.
The current design for BG/L system packaging is shown in Figure 1. (Note that this is different from a preliminary design shown in [ISSCC02] as are certain bandwidth figures that have been updated to reflect a change in the underlying signaling technology.) The design calls for 2 nodes per compute card, 16 compute cards per node board, 16 node boards per 512-node midplane of approximate size 17″x 24″x 34,” and two midplanes in a 1024-node rack. Each processor can perform 4 floating point operations per cycle (in the form of two 64-bit floating point multiply-add's per cycle); at the target frequency this amounts to approximately 1.4 teraFLOPS peak performance for a single midplane of BG/L nodes, if we count only a single processor per node. Each node contains a second processor, identical to the first although not included in the 1.4 teraFLOPS performance number, intended primarily for handling message passing operations. In addition, the system provides for a flexible number of additional dual-processor I/O nodes, up to a maximum of one I/O node for every eight compute nodes. For the machine with 65,536 compute nodes, we expect to have a ratio one I/O node for every 64 compute nodes. I/O nodes use the same ASIC as the compute nodes, have expanded external memory and gigabit Ethernet connections. Each compute node executes a lightweight kernel. The compute node kernel handles basic communication tasks and all the functions necessary for high performance scientific code. For compiling, diagnostics, and analysis, a host computer is required. An I/O node handles communication between a compute node and other systems, including the host and file servers. The choice of host will depend on the class of applications and their bandwidth and performance requirements.
The nodes are interconnected through five networks: a 3D torus network for point-topoint messaging between compute nodes, a global combining/broadcast tree for collective operations such as MPI_Allreduce over the entire application, a global barrier and interrupt network, a Gigabit Ethernet to JTAG network for machine control, and another Gigabit Ethernet network for connection to other systems, such as hosts and file systems. For cost and overall system efficiency, compute nodes are not hooked directly up to the Gigabit Ethernet, but rather use the global tree for communicating with their I/O nodes, while the I/O nodes use the Gigabit Ethernet to communicate to other systems.
In addition to the compute ASIC, there is a “link” ASIC. When crossing a midplane boundary, BG/L's torus, global combining tree and global interrupt signals pass through the BG/L link ASIC. This ASIC serves two functions. First, it redrives signals over the cables between BG/L midplanes, improving the high-speed signal shape and amplitude in the middle of a long, lossy trace-cable-trace connection between nodes on different midplanes. Second, the link ASIC can redirect signals between its different ports. This redirection function enables BG/L to be partitioned into multiple, logically separate systems in which there is no traffic interference between systems. This capability also enables additional midplanes to be cabled as spares to the system and used, as needed, upon failures. Each of the partitions formed through this manner has its own torus, tree and barrier networks which are isolated from all traffic from all other partitions on these networks.
System fault tolerance is a critical aspect the BlueGene/L machine. BlueGene/L will have many layers of fault tolerance that are expected to allow for good availability despite the large number of system nodes. In addition, the BlueGene/L platform will be used to investigate many avenues in autonomic computing.
Click here to read the complete 22-page whitepaper:
(320KB PDF download)
The full whitepaper, and the excerpts and images above, are copyright © 2002-2003 IBM Corp. Reproduced by LinuxDevices.com with permission.
Additional info
Further information on IBM's BlueGene/L supercomputer project is available on the project's website.
This article was originally published on LinuxDevices.com and has been donated to the open source community by QuinStreet Inc. Please visit LinuxToday.com for up-to-date news and articles about Linux and open source.