Nvidia GPU targets high-performance computing, too
Oct 2, 2009 — by LinuxDevices Staff — from the LinuxDevices Archive — 1 viewsNvidia has announced a “next-generation” GPU (graphics processing unit) architecture code-named “Fermi.” Employing more than three billion transistors and 512 “Cuda” cores, the architecture will let GPUs double as “general-purpose parallel computing processors,” the company says.
Nvidia explains that Fermi, announced this week at the company's inaugural GPU Technology Conference in San Jose, amounts to a third generation of products embodying its "GPU computing" model. The first generation was the G80 unified graphics/computing architecture, introduced in November 2006 and later embodied in the GeForce 8800, Quadro FX 6500, and Tesla C870 GPU products. The G80 was the first GPU to replace separate vertex and pixel pipelines with a single unified processor, the first to utilize a scalar thread processor, and the first to support C, according to the company.
The second generation was the GT200, introduced in the GeForce GTX 280, Quadro FX 5800, and Tesla T10 GPUs. GT200 increased the number of streaming processor cores — subsequently referred to as "Cuda" cores — from 128 to 240. It also added "hardware memory access coalescing," improving memory access efficiency, along with double-precision floating point support, Nvidia says.
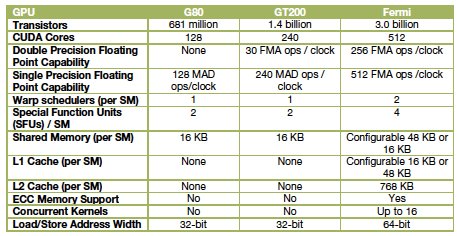
A comparison of Nvidia GPU generations
Source: Nvidia
Fermi, which will initially be implemented in a GPU containing more than three billion transistors, more than doubles the number of Cuda cores, organizing them into 16 SMs (streaming multiprocessors) with 32 cores apiece. The GPU will sport up to 6GB of GDDR5 RAM, and will also be the first product of its type to support ECC (error correcting code), the company says.
Nvidia cited the following additional features for Fermi:
- 512 Cuda cores feature the new IEEE 754-2008 floating-point standard, surpassing even the most advanced CPUs
- 8x the peak double-precision arithmetic performance of the GT200
- Nvidia Parallel DataCache, a cache hierarchy that speeds up algorithms such as physics solvers, raytracing, and sparse matrix multiplication where data addresses are not known beforehand
- Nvidia GigaThread engine, supporting concurrent kernel execution, where different kernels of the same application context can execute on the GPU at the same time (eg, PhysX fluid and rigid body solvers)
According to Nvidia, Fermi-based products will be so powerful that they can now be termed CGPUs (computational graphics processing units), and are suitable for high-performance computing (HPC) applications such as linear algebra, numerical simulation, and quantum chemistry. At Nvidia's GPU Technology Conference, Oak Ridge National Laboratory (ORNL) announced plans to build a new supercomputer that will employ the Fermi architecture, and also announced it will be creating the Hybrid Multicore Consortium, whose goals "are to work with the developers of major scientific codes to prepare those applications to run on the next generation of supercomputers built using GPUs."
 Not surprisingly, Nvidia also said it will use Fermi in its next-generation GeForce, Quadro, and Tesla GPUs, along with graphics cards (right) that employ them. The first Fermi-based GPU will reportedly be the GT300, a 40nm part that will support Microsoft's DirectX 11.
Not surprisingly, Nvidia also said it will use Fermi in its next-generation GeForce, Quadro, and Tesla GPUs, along with graphics cards (right) that employ them. The first Fermi-based GPU will reportedly be the GT300, a 40nm part that will support Microsoft's DirectX 11.
According to Nvidia, Fermi is the first product of its type that supports C++, complementing existing support for C, Fortran, Java, Python, OpenCL and DirectCompute. Fermi will also support Nexus (below), touted as "the world's first fully integrated heterogeneous computing application development environment within Microsoft Visual Studio."
Nvidia's Nexus
(Click to enlarge) Source: Nvidia
Nexus is composed of the following three components, according to Nvidia:
- The Nexus Debugger, a source code debugger for GPU source code, such as CUDA C, HLSL and DirectCompute. It supports source breakpoints, data breakpoints and direct GPU memory inspection. All debugging is performed directly on the hardware.
- The Nexus Analyzer, a system-wide performance tool for viewing GPU events (kernels, API calls, memory transfers) and CPU events (core allocation, threads and process events and waits) on a single, correlated timeline.
- The Nexus Graphics Inspector, which provides developers the ability to debug and profile frames rendered using APIs such as Direct3D. Developers can pause an application at any time and inspect the current frame, examining draw calls, textures, and vertex buffers, the company says.
Jen-Hsun Huang, co-founder and CEO of Nvidia, stated, "It is completely clear that GPUs are now general purpose parallel computing processors with amazing graphics, and not just graphics chips anymore. The Fermi architecture, the integrated tools, libraries and engines are the direct results of the insights we have gained from working with thousands of CUDA developers around the world. We will look back in the coming years and see that Fermi started the new GPU industry."
Availability
Nvidia said a beta version of Nexus will be available on Oct. 15, and is offering more information from its website, here. Meanwhile, overall background on Fermi, including a downloadable white paper, may be found here.
No word was provided on when Fermi architecture will be provided on discrete graphics cards, much less embedded devices. As noted earlier in this story, however, it's rumored that GT300-equipped cards will be available during the first half of 2010.
This article was originally published on LinuxDevices.com and has been donated to the open source community by QuinStreet Inc. Please visit LinuxToday.com for up-to-date news and articles about Linux and open source.