ELJonline: Automating the Physical World with Linux, Part 2: Expanding Control Automation
Jul 1, 2001 — by LinuxDevices Staff — from the LinuxDevices Archive — viewsIn this article, Bryce gets us out of the house and into our new resort.
This article is the second in a series of three introducing the field of control automation and its use with Linux. In this second article, I'll cover the concept of control automation in increased detail, describing simple as well as computationally intensive types of control that Linux-based computers can handle. I'll also discuss distributing control functions among multiple computers so a single computer does not have to perform all the control functions. Finally, I'll describe some reasons why this might be advantageous or even required.
With the arrival of the vacation season in the Northern Hemisphere, I'll also introduce a hypothetical resort. For control automation applications, a resort is a wonderfully lavish environment with golf courses, pools, landscaping, fire and security alarms, lights, climate-controlled guest and banquet rooms, lighted walkways, automatic access controls and other items that are ripe for control automation solutions. We'll apply the sprinkler controller and temperature control ideas from the first article to various items in this environment.
Fundamental Concepts from Part 1
The first article introduced the examples of a sprinkler system and a simple temperature control system (see ELJ May/June 2001). The sprinkler system turned on the valve for a single watering zone at a given time and day. The simple temperature control maintained the temperature of a room, by turning on a heater or a fan, based on the room's current temperature.
The first article also covered fundamental requirements for control automation: the data acquisition hardware, called the I/O unit; the software control algorithm and its loop time used to automate the control task; and the use of Ethernet as a link between the computer running the control program and the I/O unit. (In control automation the computing device running the control program is rather imaginatively called a controller or embedded controller. We'll use these terms from now on to refer to a Linux-based computer running the control algorithm.)
The I/O unit provides a physical interface from the controller to the environment. For the examples in the first article, I could have performed the control tasks manually by reading a temperature gauge, watching the clock, turning on a sprinkler valve, turning on a fan or turning on a heater. An I/O unit allows the controller to accomplish the same physical tasks without human intervention.
The software control algorithm describes how a device must be controlled. In the first article, I examined the specific tasks I needed to perform manually in order to control the sprinkler and temperature control systems. I then developed a software control algorithm to perform these tasks. I also added other functions to initialize and terminate the program. While this may sound oversimplified, it's not; most automated controls are based upon manual actions.
The loop time is the interval or rate at which the software control algorithm examines and updates the system. Our initial examples were intentionally slow and unresponsive compared with Linux process times and performance. This approach avoids the complexities of dealing with process task switching and process latency times.
Finally, we also looked at the use of Ethernet networking to link an embedded controller and one or more I/O units (see Figure 1). Using Ethernet offers several benefits: network adaptors are well supported, which avoids the need to create a device driver, and external Ethernet-based I/O hardware lets us maintain I/O hardware without having to interrupt or open the controller. Additional advantages to using Ethernet networking include its common installation in many facilities and the easy expandability needed for commercial systems. We'll rely on this ability to expand when we add additional control functions later in this article.
Expanding the Controller
Most of you are probably thinking that sprinkler and temperature controls are conceptually trivial. They are. These types of controls are implemented on silicon stamps (powerful compact microcomputers) and are readily available in any hardware or home improvement store. Running these controls on an embedded controller won't even exercise Linux. I'd be surprised if CPU usage exceeded 0.1% with this kind of control application.
The minor processor utilization allows us to add more sprinkler zones and temperature controls. Even modestly powered embedded hardware could control several hundred such zones before any real workload is created. For example, a resort with golf courses, lawns, access controls, tropical gardens, fountains, air conditioning and lighting could be controlled entirely by a single application running on a single embedded controller.
How is a control system expanded? The obvious answer is more software development and additional I/O units. But how should you approach this expansion? What fundamental questions must be answered before planning the expansion?
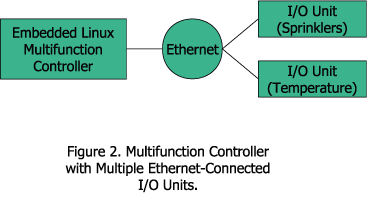
When I plan to expand a control system, I first group similar control elements together. I might group sprinkler zones in one function and temperature control in another, for example (see Figure 2). The grouped functions operate in a continuous control loop. Listing 1 shows an example of grouped functions in C pseudo-code.
Specific programming environments for Linux also provide multithreading capability. We could run the sprinkler control tasks at the same time we run the temperature tasks.
Multithreading is useful since independent threads may take advantage of unused or sleeping time by the other tasks. For more information on how Linux implements multithreading see the excellent Pthreads Programming: A POSIX Standard for Better Multiprocessing by Bradford Nichols, et. al. (O'Reilly & Associates, 1996).
Introducing Computationally Intensive Controls
Up to now, we've focused on simple controls. The sprinkler and room temperature controls use a clock and a temperature input, respectively, as the state variable (that is, the state of our system). Our control algorithms simply compare the current time to a desired on-time for the sprinkler, or they check whether the room temperature is greater or less than our desired setting.
What I call computational control is a broad field. Many control systems rely on simple-to-complex arithmetic equations to perform control tasks. Our previous examples are essentially bang-bang controllers, so named for their on-off-on nature. These simple controls rely on Boolean states to provide control. Sprinkler valves are either on or off. Fans are either on or off. It's time to water or not. You get the idea.
But some types of control are more computationally intensive. Proportional control is one such type of control. Driving a car or riding a bicycle is a good example of a proportional function. Normally we steer based on the apparent errors our eyes see, which provides smooth, continuous control of the vehicle. The more you sense you are off center, the more you steer back toward the center. Your correction is continuous from zero to maximum left or maximum right. Imagine, however, trying to steer a vehicle if the steering wheel could only be maximum right or maximum left, not in between. The car would whip between full left and full right, giving you and any unlucky passengers a memorable ride indeed.
Proportional control is a control method that allows corrections to be made based on a proportion of the error. The error is the difference between a system's target value (what the system should be) and its actual value (its current measurement). This error is computed into a drive command to correct the system. Many highly accurate control systems are based on this control architecture.
Control applications using proportional control are a bit more difficult to develop. While I can imagine how to turn on my sprinklers, it's harder to create an equation that describes my method of steering (or my eyes' ability to identify the road). Also, computing arithmetic equations demands more computational time, as these equations may encompass integer or even floating-point operations. These functions require more time to process and have larger data types to transfer between the processor and the memory. In short, proportional control tends to be a science due to its increased sophistication.
Adaptive control is another computationally intensive type of control that essentially self-corrects based on historic trends and a set of correction rules. The benefit to this type of control is the ability to tune itself so changes in system performance do not require constant readjustment by the user.
In the past, I've worked with other control algorithms that rely on equations based on regression, matrix algebra and recursive processing and are so computationally demanding they almost contradict the notion of real-time control. Fortunately, computer hardware has become considerably more robust and affordable since those days. Some of the more elaborate research and development solutions from a decade ago could be adequately solved with today's high-end embedded controllers.
At this point, we've been operating on the assumption that our embedded controller can handle any control tasks we give it. The reality is the controller is limited, typically in its processing capability or software complexity. A controller's ability to handle control tasks depends upon several factors: the control methods used, the number of devices to be controlled and, finally, the number of other controllers that can be used in the control system.
Introducing Distributed Systems
Adding another controller to the control system is a natural response when my single-control computer becomes saturated or when the application is too complex to handle multiple tasks. Additional controllers may also be added to a control system for other reasons, such as to isolate system interactions and provide additional locations where maintenance personnel can examine or change the system's status.
Let's apply distributed control to the lavish resort described earlier. Room temperature controls and sprinkler controls are typically unrelated, and these two separate systems could control their own areas without any intervention. This is the simplest type of control distribution: two distinct software applications on two distinct controllers.
Controller distribution may be based on the need for a coordinated response by multiple systems or on physical planning considerations. A safety system may need to inspect smoke detectors, manual alarms, temperature faults or panic buttons more often than a sprinkler system. The safety system may also have to comply with local building codes; for example, codes typically require safety systems are dedicated without any other intervention. Some projects I've worked on had safety systems that required a redundant power supply and/or a fault-tolerant power supply. For sprinkler controls, these requirements are typically not necessary and are cost-prohibitive.
Controller distribution may also be based on the location of the system being controlled. In our large resort, for example, several guest lawns could be separated by miles. It would be difficult for the maintenance crew to inspect a water valve at one such lawn and then radio a command to the central office to activate a watering zone. Having a local controller at a lawn would allow the maintenance crew to inspect the controller and open or close the water valve on the spot.
Failure is another issue related to distributed systems. The control system requirements may specify a certain action or result if a subsystem controller fails. If our resort had a single controller and it failed, everything would stop, sprinklers, room temperature controls, lighting, etc. Designing around failure is itself an art. I've dedicated the third article of this series to the topic of system failure and how to avoid it.
Coordinating Distributed Systems
In some cases these independent control systems would require coordination. In the resort, access controls could prevent hotel guests from walking on the lawn when watering is about to start or is in progress. They could also interact with the lighting systems to turn them off during watering to save electricity. Safety systems could trigger the access controls to turn on high-visibility safe route signs and open all doors. The safety system could also trigger the lighting system to turn on all available lights and pathway lighting so guests can easily find their way to safety. Figure 3 lists the requirements to connect two or more separate embedded systems.
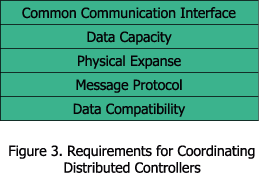
The first requirement is a common communication interface that supplies a path for data to be shared among different controllers. It must be widely supported and accepted, and it must be available on potential candidates for the hardware controller. This interface must also have long-term support, as the life cycle of a control system may exceed ten or more years.
Data capacity is the second requirement to connect separate systems, and the communication interface throughput must be significantly robust. This data interface needs to adequately supply the data requirements of the current system and also be able to accommodate possible upgrades and additions to the control system during its life cycle. If the interface can't accommodate future updates, it should at a minimum be capable of bandwidth expansion.
Physical expanse is critical as our resort may sprawl over 20 square miles; therefore, this communication interface must be able to operate adequately over excessive distances. A communication interface that reaches a few meters simply won't do. Accurate distance calculations should be compared against design plans of the resort to insure distances are within acceptable tolerances.
Message protocol is important because messages will commonly be exchanged between our controllers. While initial installations may use the exact same hardware architecture, this may not be the case throughout the life cycle of the control system. The diversity of Linux architectures allows you to use the best architecture (performance, cost, availability, size, power requirements, etc.) for the application. A replacement controller in the future, for example, may be a different architecture altogether. Another important Linux advantage for controllers is that GPLed code may be ported to another architecture or operating system. It's imperative that considerations in common protocols be emphasized for portability and long-term code support.
Finally, all of our control systems must be able to understand and interpret the message data that each one is sending to another, so data compatibility is a must. While this is typically not a fundamental problem, problems can be created by different core processors manufactured by competing companies. Again, Linux's diverse architecture support raises this concern. In general, data may be transferred as readable ASCII data (a standard character-representation format) or as unreadable binary data. Both have their strengths. Binary data is an exact computer representation and requires little overhead for a computer to send or receive. Using ASCII adds an overhead for binary-to-ASCII and ASCII-to-binary conversion. Debugging binary data may be difficult, while ASCII is relatively straightforward, due to its readability. Binary message formats are typically faster because there is little overhead to process the information. An evaluation of binary vs. ASCII requires some broad considerations when dealing with the multi-architecture nature of Linux.
Our Distributed Controller Interface
Ethernet is an excellent solution for our distributed controller interface, as it is a commercially accepted interface available on virtually every computer architecture. Therefore, it supports our commonly available connectivity solution.
Our control functions typically need to inspect the systems' states every second or so, which is a minimal bandwidth requirement for Ethernet. With 100Mbps and 1Gbps fiber and copper networking solutions available, a higher bandwidth control system could be implemented later. Also, if our resort had an existing Ethernet network installed and its bandwidth would not be impacted, our system could be added to the extant network.
Our sprawling resort may have cables running distances up to several miles, whereas Ethernet has fiber options that range up to several kilometers in length. With a fiber installation, our large resort could be a single Ethernet segment. If the expanse is excessive, a WAN and a routed multisegment network could be implemented. Keep in mind the Internet is an extremely expansive, routed network.
While many networking protocols can be used to send messages over Ethernet, I prefer TCP/IP (and its counterpart UDP/IP). Using a widely accepted protocol gives more control systems the capability of communicating with my devices. Also, the addressing implementation allows for a reasonable number of devices to be accessible on our network. Some systems use raw proprietary protocol sockets. With considerations of GPL available code, raw sockets may be difficult to maintain across other systems, particularly non-Linux operating systems. While there is additional overhead in TCP/IP, it is insignificant compared to the update rates of our systems.
I would use ASCII (readable) messages for my message data exchange. I like the ability to read messages and possibly use other tools, such as Telnet, to communicate to another device.
A Coordinated Distributed System Example
Returning to our resort, I'd like to propose a distributed control system for the special events area with the following isolated control functions: an embedded controller for the lawn, an embedded controller for lawn lighting, a separate controller for pathway lighting and an embedded controller for area access controls.
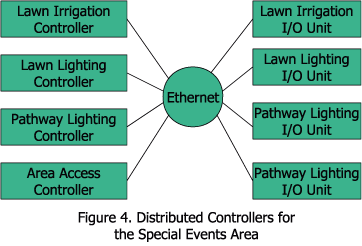
If each subsystem were isolated without the benefit of receiving any requests, then each system would operate using its own control program without coordinating with other controllers. With the implementation of our network and data-exchange requirements, we can introduce coordination between control subsystems. Here's an example:
- The irrigation controller identifies it needs to water the special events lawn. It sends a command identifying the area to be watered across our network. (We'll call this message a pre-irrigation warning.)
- The affected systems receive the message, identify it's a pre-irrigation warning and take appropriate actions:
- The lighting system reduces lighting for the special events lawn to encourage any guests present to depart and to dissuade other guests from entering the area.
- After allowing a few minutes for guests to leave the special events lawn, the access control system closes gates to the area to prevent guests from entering.
- The pathway lighting system turns off lights on pathways that lead to the special events lawn.
- Once a delay has expired on the irrigation controller, it turns on the sprinklers.
The addition of communication between subsystems lets us make these isolated, distributed controllers operate as a loosely coupled team. In this example, with each specialized function, we were able to provide a passive and automatic means of preventing guests from getting wet by implementing a few command messages. Other features that may be implemented are limited only by your imagination.
Distributed System Coupling
Perhaps the last consideration in a distributed system implementation is coupling. This is usually a quantitative assessment of how loosely or tightly the systems interact or to what extent one system function relies on another system function. Our special events lawn example represents a loosely coupled system, since the failure of a subsystem would not result in a failure of the other subsystems. The higher the coupling, the more interactive the participation of a single distributed controller in the overall control solution.
Coupling may affect the distributed system design. Typically, the higher the coupling, the more responsive the communications interface must be. It may be necessary to consider binary format messages, higher bandwidth communications and higher throughput controllers. Failure and recovery is also an important issue. What response should our system take if a critical unit fails?
System planning and design architecture can relieve the level of system coupling. However, in very distributed systems, centralizing the entire system is impossible. Careful evaluation and planning determines the complexity or simplicity of the solution.
Conclusion
In this article, I've expanded our simple sprinkler and temperature controls into a more diverse system capable of automating a large commercial resort. The additional tasks of controlling lights, access or any other feature are based on simple control algorithms. While there are applications that might use significantly more complex control algorithms, a great number of the controls that exist in the world are quite simple and easily available.
I also introduced distributed control as a means for increasing control capacity, isolating critical and noncritical functions and simplifying the control architecture. However, distributed control requires additional functions. Distributed systems may have to exchange data to synchronize coordinated functions. Because Linux is available for many different processor architectures, data-exchange considerations must also be evaluated. Yet, with so many processor architectures currently available, these issues are pertinent to allow future cost-effective growth and maintenance of this system.
I've still been avoiding an extremely important issue: failure. Accounting for failure is as critical to a control system as the design itself. What happens, for example, if our resort's irrigation controller stops, and the golf course sprinklers stay on? There's the course damage, the cost of the water, the loss of revenues — talk about a water hazard! The inability of a control system to deal with the failure of a device — or failure of the system itself — may have catastrophic effects on people and property.
I'll discuss failure in the third and final article in this series. We'll look at approaches to designing and implementing a control system that will improve system reliability (or lower the probability of failure). I'll also describe active and passive methods to produce a safe control system.
 About the author: Bryce Nakatani ([email protected]) is an engineer at Opto 22, a manufacturer of automation components in Temecula, California. He specializes in real-time controls, software design, analog and digital design, network architecture and instrumentation. He is considering a short vacation at the lavish resort.
About the author: Bryce Nakatani ([email protected]) is an engineer at Opto 22, a manufacturer of automation components in Temecula, California. He specializes in real-time controls, software design, analog and digital design, network architecture and instrumentation. He is considering a short vacation at the lavish resort.
Copyright © 2001 Specialized Systems Consultants, Inc. All rights reserved. Embedded Linux Journal Online is a cooperative project of Embedded Linux Journal and LinuxDevices.com.
This article was originally published on LinuxDevices.com and has been donated to the open source community by QuinStreet Inc. Please visit LinuxToday.com for up-to-date news and articles about Linux and open source.