Nvidia taps GPUs for ‘world’s fastest’ parallel processing
May 17, 2011 — by LinuxDevices Staff — from the LinuxDevices Archive — 2 viewsNvidia announced a new parallel processor for the high performance computing (HPC) market, based on its GPU (graphics processing unit) architecture. Initially offered in servers from HP, the Tesla M2090 is a PCI Express x16 card touted as “the world's fastest parallel processor for high-performance computing,” with up to 665 Gigaflops of performance.
Nvidia's M2090 harnesses Nvidia's "next-generation" GPU architecture, code-named "Fermi," which was first announced in October 2009 (see later in this story for background). Employing the GPUs for general-purpose parallel computing, the board does not run Windows or Linux directly but, instead, is designed to run C, C++, OpenCL, DirectCompute, or Fortran while a host's CPU performs other tasks, according to the company.
In January 2010, we covered Nvidia's first parallel processing products, the C2050 and C2070. These PCI Express Gen2 cards respectively occupied one or two slots in a workstation, and included either 3GB or 6GB of onboard GDDR5 memory.
Nvidia also offered the M2070 and M2050, which offered the same technology but came with passive heatsinks rather than active cooling. Designed to be offered only in pre-approved system solutions, they're still on sale, but the M2090 (below) now bolsters this product line at the high end.

Nvidia's Tesla M2090
(Click to enlarge)
The x2070 and x2050 products were originally claimed to offer 512 "Cuda" processor cores, delivering from 520 to 640 Gigaflops of double precision floating point performance. Nvidia now lists them as having 448 Cuda cores each, with 515-gigaflop performance.
Timothy Prickett Morgan writes in an article for The Register that Nvidia apparently had some yield and heat issues with its initial Fermi chips, leading to the shortfall in specs. But, he adds, the new M2090 features a new tape-out of the Fermi design using Taiwan Semiconductor Manufacturing Corp's 40nm process.
As a result, the M2090 how has all 512 Cuda cores activated. Core clock speed is up by 13 percent to 1.3GHz, and GDDR5 memory speed is up by 18.6 percent to 1.85GHz, Morgan says.
For its part, Nvidia says the M2090 delivers 665 gigaflops of peak double-precision performance, "enabling application acceleration by up to ten times compared to using a CPU alone." In the latest version of Amber 11 — one of the most widely used applications for simulating behaviors of biomolecules — four Tesla M2090 GPUs coupled with four CPUs delivered record performance of 69 nanoseconds of simulation per day, the company adds. (In contrast, the fastest Amber performance recorded on a CPU-only supercomputer is said to have been 46 ns/day.)
Ross Walker, assistant research professor at the San Diego Computer Center and principal contributor to the Amber code, is quoted as saying, "This is the fastest result ever reported. With Tesla M2090 GPUs, Amber users in university departments can obtain application performance that outstrips what is possible even with extensive supercomputer access."
In addition to Amber, the Tesla M2090 GPU is ideally suited to a wide range of GPU-accelerated HPC applications, according to Nvidia. These are said to include: molecular dynamics applications, NAMD and GROMACS, computer-aided engineering applications, ANSYS Mechanical, Altair Acusolve and Simulia Abaqus, earth science applications, WRF, HOMME and ASUCA, oil and gas applications, Paradigm Voxelgeo and Schlumberger Petrel, plus other key applications such as MATLAB, GADGET2 and GPU-BLAST.

HP's ProLiant S390s G7
Nvidia says the Telsa M2090 will be offered in servers such as the HP ProLiant S390s G7 (above). This device incorporates up to eight of the boards in a half-width 4U chassis and, "with a configuration of eight GPUs to two CPUs, offers the highest GPU-to-CPU density on the market," according to the company.
Glenn Keels, director of marketing for HP's Hyperscale business unit, stated, "Clients running intensive data center applications require systems that can process massive amounts of complex data quickly and efficiently. The decade-long collaboration between HP and Nvidia has created one of the industry's fastest CPU to GPU configurations available, delivering clients the needed processing power and speed to handle the most complex scientific computations."
Background on Nvidia's Fermi
Fermi, announced in 2009 at Nvidia's inaugural GPU Technology Conference in San Jose, amounts to a third generation of products embodying the company's "GPU computing" model. The first generation was the G80 unified graphics/computing architecture, introduced in November 2006 and later embodied in the GeForce 8800, Quadro FX 6500, and Tesla C870 GPU products. The G80 was the first GPU to replace separate vertex and pixel pipelines with a single unified processor, the first to utilize a scalar thread processor, and the first to support C, according to the company.
The second generation was the GT200, introduced in the GeForce GTX 280, Quadro FX 5800, and Tesla T10 GPUs. GT200 increased the number of streaming processor cores — subsequently referred to as "Cuda" cores — from 128 to 240. It also added "hardware memory access coalescing," improving memory access efficiency, along with double-precision floating point support, Nvidia says.
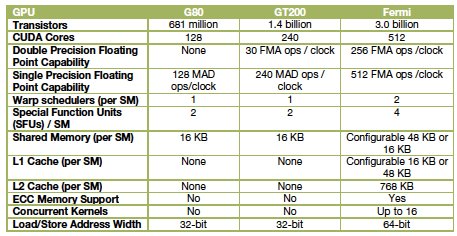
A comparison of Nvidia GPU generations
Source: Nvidia
Fermi, implemented in a GPU containing more than three billion transistors, more than doubles the number of Cuda cores, organizing them into 16 SMs (streaming multiprocessors) with 32 cores apiece. Sporting up to 6GB of GDDR5 RAM, Fermi is the first product of its type to support ECC (error correcting code), the company says.
In October, Nvidia claimed the following additional features for Fermi:
- 512 Cuda cores feature the new IEEE 754-2008 floating-point standard, surpassing even the most advanced CPUs
- 8x the peak double-precision arithmetic performance of the GT200
- Nvidia Parallel DataCache, a cache hierarchy that speeds up algorithms such as physics solvers, raytracing, and sparse matrix multiplication where data addresses are not known beforehand
- Nvidia GigaThread engine, supporting concurrent kernel execution, where different kernels of the same application context can execute on the GPU at the same time (eg, PhysX fluid and rigid body solvers)
According to Nvidia, Fermi was the first product of its type to support C++, complementing existing support for C, Fortran, Java, Python, OpenCL and DirectCompute. Fermi also supports Nexus (below), touted as "the world's first fully integrated heterogeneous computing application development environment within Microsoft Visual Studio."
Nvidia's Nexus
(Click to enlarge) Source: Nvidia
Nexus is composed of the following three components, according to Nvidia:
- The Nexus Debugger, a source code debugger for GPU source code, such as CUDA C, HLSL and DirectCompute. It supports source breakpoints, data breakpoints and direct GPU memory inspection. All debugging is performed directly on the hardware.
- The Nexus Analyzer, a system-wide performance tool for viewing GPU events (kernels, API calls, memory transfers) and CPU events (core allocation, threads and process events and waits) on a single, correlated timeline.
- The Nexus Graphics Inspector, which provides developers the ability to debug and profile frames rendered using APIs such as Direct3D. Developers can pause an application at any time and inspect the current frame, examining draw calls, textures, and vertex buffers, the company says.
Availability
Nvidia did not spell out pricing or availability for the Tesla M2090, but the boards appear to be orderable now in the HP server mentioned in this story. More information can be found on Nvidia's Tesla product page.
Jonathan Angel can be reached at [email protected] and followed at www.twitter.com/gadgetsense.
This article was originally published on LinuxDevices.com and has been donated to the open source community by QuinStreet Inc. Please visit LinuxToday.com for up-to-date news and articles about Linux and open source.